
Hi Mike,
On 18/03/15 05:23, Michael Turquette wrote:
Hi Dietmar,
Quoting Dietmar Eggemann (2015-03-17 10:13:39)
Hi Mike,
On 16/03/15 22:08, Michael Turquette wrote:
Instead of tracking "requests" by tagging cpus that have updated stats in a cpumask we could track "constraints", where a constraint is the return value of get_cpu_usage stored in a per-cpu variable whenever a task is migrated. (or whenever the load contribution for a task change significantly. more on that at the bottom)
I'm not sure this is necessary. The information that we have a cpu with a request is sufficient because we can always get the cpu usage just before we kick the kthread. (exactly what you do right now).
Well, I've never thought that calling get_cpu_usage from the kthread was really a good idea. Shouldn't there be some locking around accesses to the cfs_rq data structures?
Heaven forbid, me neither :-)
This is one reason why I was considering migrating the data that the governor wants (per-cpu usage data) into per-cpu atomics, as opposed to iterating over every cpu with get_cpu_usage or utilization_load_avg_of (as it was called in my original series). It is basically a poor-mans IPC mechanism.
OK, for me it sounds like you want to store cpu usage in per-cpu atomics in update_entity_load_avg() to avoid iterating the 'policy->cpus) in arch_eval_cpu_freq().
IMHO, iterating over cpus to read stuff is fine.
E.g. in:
load_balance()->find_busiest_group()->update_sd_lb_stats()->update_sg_lb_stats()
for_each_cpu_and(i, sched_group_cpus(group), env->cpus)
We don't hold the locks for 'i' when we read e.g. the weighted cpuload (cpu_rq(cpu)->cfs.runnable_load_avg) (or the utilization for that matter).
If accessing cfs_rq without locking is actually safe then please let me know.
The issue is that we could see a lot of requests during the time the em mechanism is throttled.
Why don't you just add:
cpumask_set_cpu(cpu_of(rq), &update_cpus);
if (energy_aware() && !cpumask_empty(&update_cpus)) arch_eval_cpu_freq(&update_cpus);
into task_tick_fair() to detect cpu usage changes due to a single task running in case there is no enqueue/dequeue happening?
Sure, and putting the change into update_entity_load_avg as I suggested achieves the same end result. That data will never be more stale than the rest of the PELT values.
True, I was talking about the fact that updating PELT might happen way before the throttling time is over so before you kick the kthread again you would have to update cpu usage any way. But on second thought this might not be a problem (the staleness of cpu load) after all. If nothing is running on that cpu it's probably (nohz) idle and if there is, then we get (de/en-queues or ticks) which then could set the stage for arch_scale_cpu_freq() to do its thing. Not sure if this could be an issue for scaling frequency down though?
Also I've been thinking a lot about the combination of throttling and the kthread. I'm starting to think that this design would end up being periodic (based on the throttle period), which isn't so different from how legacy CPUfreq governors work today. Do you have time to chat on the phone about this? I'll send out an invite.
Sure.
[...]
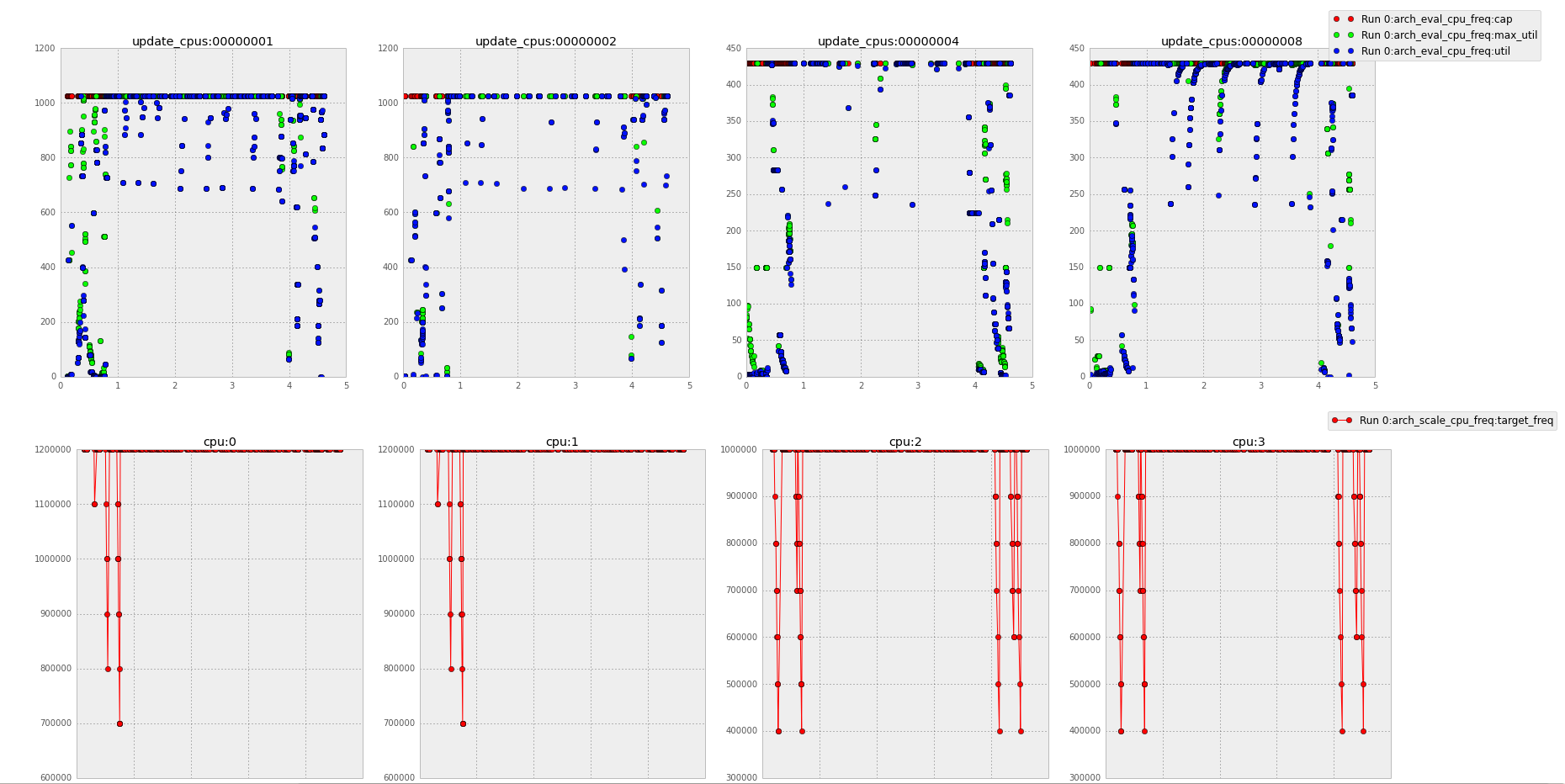
Thanks for the graph. I'll state some assumptions. Please let me know if I am wrong.
cpu0 & cpu1 are A15s whose max capacity is 1024. You are running some use case that mostly keeps those cpus fully utilized (or more correctly, over-utilized) at the highest frequency, which is why the red dot stays capped at SCHED_LOAD_SCALE.
You're right here.
The workload is 'sysbench --test=cpu --num-threads=8 --max-time=3 --max-requests=100000 run
I further attached the plots of 'cap', 'util', 'max_util' (trace in arch_eval_cpu_freq()) and 'em->target_freq' (trace in arch_scale_cpu_freq()) for this particular test run.
cpu2 & cpu3 seem to show the same behavior but the different scales make it hard to be certain. I'll assume that they are both running at their highest frequency and over-utilized for most of the use case.
Yes.
Assuming what I stated above is correct, this seems like useful data to me. The point of having the per-cpu atomic storage is to have lockless access to this useful info. If the cpufreq thread needs to iterate over this data to find the most utilized cpu in the freq domain then the per-cpu version of this removes any requirement to lock the cfs_rq structures.
IMHO, just to read cfs_rq load/utilization data, we do not need to hold the cfs_rq lock.
information that a cpu requested a freq change. In case of 'pending requests' happening in a throttle period, what is the value of the per (cfs_)rq signal 'cpu usage' any way? It could be a stale value once the throttle period is over.
My proposal was to update the per-cpu data in update_entity_load_avg every time the load contribution changes. Thus it would never be stale (or no more or less stale than the rest of PELT values). Please let me know if I have any holes in that assumption.
OK, but since reading of cfs_rq utilization on all cpu's of the frequency domain is possible in arch_eval_cpu_freq(), why bother?
When the governor thread finally is ready to perform a cpu frequency transition it has already had the latest data *pushed* to it via the shared per-cpu atomic.
IMHO, we don't need this per-cpu atomic.
- colors in attached diagram (data from TC2 (2 A15, 2 A7) in
update_entity_load_avg()
The above untested snippet only cares about the CFS usage. In the future we might want to aggregate it with DL and RT usage as well, or we might have a per-class, per-cpu atomic.
IMHO,we should focus on CFS (with the underlaying PELT mechanism) for now and solve this smaller set of problems first:
(1) Fixup the 'struct cpumask update_cpus' problem.
Can you elaborate on what this problem is? I wanted to replace this cpumask since I am not trying to solve the CONFIG_FAIR_GROUP_SCHED problem where a sched_entity is not a task. Is there another problem besides that?
No, I don't think so. 'update_cpus' is right now only a single cpu. And even for group scheduling we're only dealing with one cpu (cpu_of(rq).
Morten pointed out earlier that we might need a mask if we want to tell the Sched-DVFS to change the frequency for more than 1 freq domain with kicks of both kthreads (e.g. in load balance on DIE level, where dst_cpu and src_cpu belong to two different freq domains). Maybe not for this iteration ...
(2) Fix the problem that we evaluate the cpu_usage exactly at the end of a throttling period if there were 'pending requests' even if there are no events at this moment.
Yes, I agree this is a problem.
Cool.
(3) kick the logic whenever we cross the up_threshold for scaling cpu frequency up.
This can be taken care of by either kicking the thread in update_entity_load_avg or by adding the thread-kick to every caller of that function, namely task_tick_fair as you pointed out.
OK.
Any ideas on this approach?
Further thoughts:
Assuming that the above idea is agreeable, one of the questions I am grappling with is whether we should store the usage in a per-cpu variable or if we should add it as a member to struct rq (in which case it would be a sum of usage from every sched class).
I am currently only looking at the CFS-centric, per-cpu atomic variable method, following the philosophy of Keep It Simple, Stupid. However putting it in struct rq has benefits:
I like this 'CFS-centric, per-cpu atomic variable method' because IMHO it gives the playground for everything we need right now to let it work with EAS.
I am confused. At the top of this mail you said you didn't see the advantage, but you like it here. Hopefully we can discuss it over the call.
Sorry about that, I thought you were referring to the existing approach (the atomic em->need_wake_task). I should have spotted the ' ... per-cpu ...' in the sentence above :-)
Like I said before, I don't see the advantage of having a per-cpu atomic for the cpu load.
Cheers,
-- Dietmar
[...]
{kind=link}