
Kernel folks,
Sandia is setting up their new Astra cluster[1] based on ThunderX2 and they found an issue on RedHat's kernel (4.14, I know, not upstream) related to Mellanox drivers. Coincidentally, Huawei also found the same problem (see the conversation below).
The attached patch is Sandia's attempt to solve the problem, but apparently, it just makes it better, doesn't solve it. Here's what they said about it:
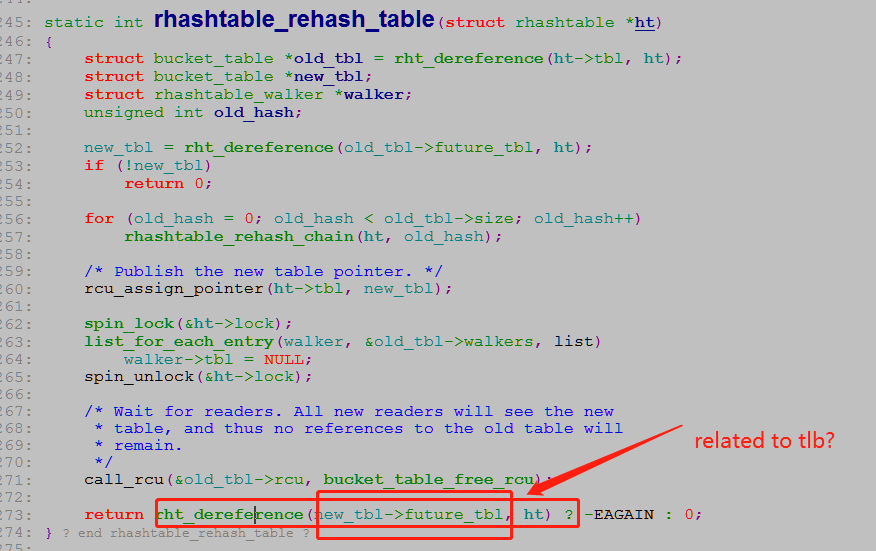
"The only difference compared to stock rhel7.6 is the following patch. This mitigates the issue, but does not fix the root cause. The original bug is rare, requiring for example repeated HPL runs on 288 nodes to trigger it on ~4 nodes overnight. When the bug hits, one CPU gets stuck 100% in kworker. This is because the rht_shrink_below_30() call in rht_deferred_worker() returns -EEXIST indefinitely, causing the work to be requeued at the end of rht_deferred_worker() (i.e., the deferred work in rht_deferred_worker() fails so it requeues itself to try again later, only it always fails later, hence the infinite loop)."
"I suspect there is a subtle race condition in the Linux rhashtable code and/or RCU code on aarch64, perhaps due to memory consistency model differences compared to x86. It may be fixed in kernel.org mainline, as there have been a lot of changes compared to what's in the rhel 7.6 kernel."
I have pointed them to the ERP kernel, which works well with ThunderX2s in our lab, and we'll see how that goes, but just wanted to make sure there isn't some known issue around rhashtable, netorking or infiniband.
cheers, --renato
[1] https://share-ng.sandia.gov/news/resources/news_releases/arm_supercomputer/
---------- Forwarded message --------- From: Pedretti, Kevin T ktpedre@sandia.gov Date: Fri, 11 Jan 2019 at 19:16 Subject: Re: [EXTERNAL] Re: [Linaro Collaborate] HPC SIG > Weekly Sync Minutes To: Pak Lui pak.lui@linaro.org Cc: Renato Golin renato.golin@linaro.org
Yes, this is exactly what we saw as well. Our workaround fix was to return early from rht_deferred_worker on one specific error, -EAGAIN. If -EAGAIN is the err, we just don’t requeue the work. It seems that if -EAGAIN is returned once, it will be returned forever, causing the infinite requeuing loop. This is likely a leak of some sort, but works around the issue well enough for our purposes.
Kevin
*From: *Pak Lui pak.lui@linaro.org *Date: *Friday, January 11, 2019 at 12:11 PM *To: *Kevin Pedretti ktpedre@sandia.gov *Cc: *Renato Golin renato.golin@linaro.org *Subject: *Re: [EXTERNAL] Re: [Linaro Collaborate] HPC SIG > Weekly Sync Minutes
Have to fly now but here's what we see. I'll check email again later. Not sure if the image show up correctly.
The following is the call stack, rht_deferred_worker call queue_work_on, if rht_deferred_worker get error, it will repeat to call work queue that make the cpu not released.
Suspect some kernel schedule problem between kernel and CPU.
[root@node0 tracing]# echo 0 > trace
[root@node0 tracing]# head trace
# tracer: function
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
kworker/15:1-161 [015] .... 14053.007473: queue_work_on <- rht_deferred_worker
[image: image.png]
[image: image.png]
On Sat, Jan 12, 2019 at 2:55 AM Pedretti, Kevin T ktpedre@sandia.gov wrote:
Hi Pak,
We saw this same issue with the RHEL7.5 kernel as well and were hoping that RHEL7.6 fixed it. Finally we bit the bullet and started adding printk's all over the place. The rhashtable that it was hanging on was not Mellanox related, rather it was almost always the built-in netlink rhashtable. That's not to say it wasn't induced by MOFED HCOLL somehow, and this seems plausible. Glad to hear you have a reproducer and are working with Mellanox. Our reproducer takes an overnight run on lots of nodes to hit it.
Kevin
{kind=link}
{kind=link}
{kind=link}
{kind=link}