
Dear Sarbojit, Agreed with your point, thanks for raising it..
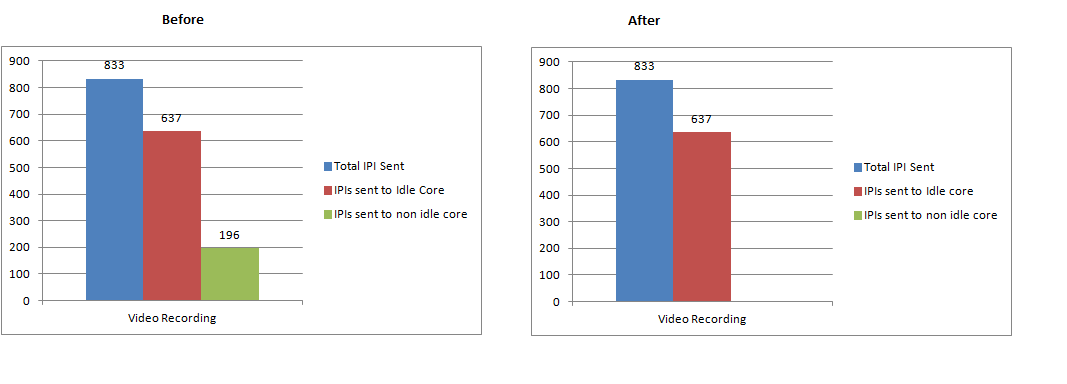
There was one issue in the total no of interrupt count in the previous chart preparation, actually the total no of interrupt is equal to the interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big domain CPUs. I just updated the below mentioned chart with the related data.
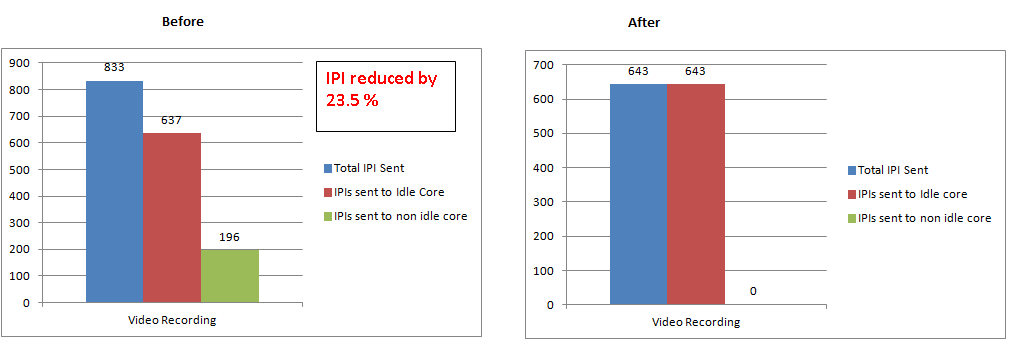
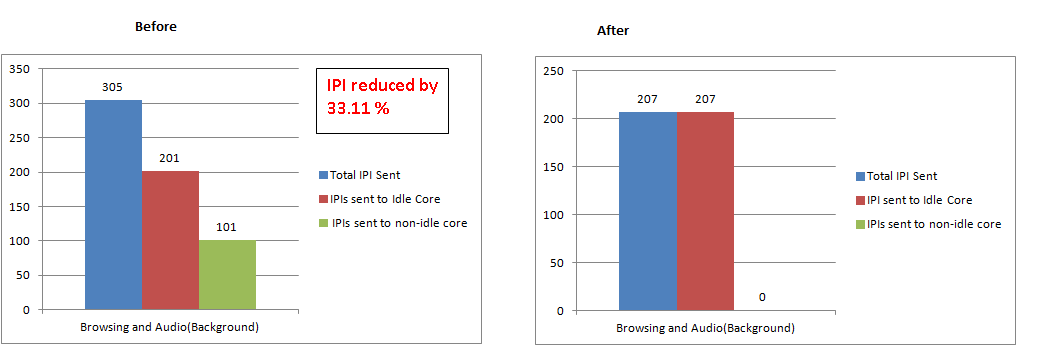
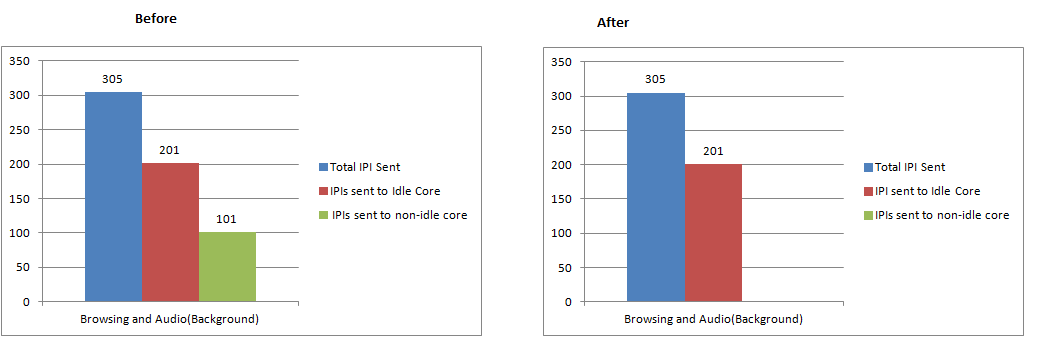
Case 1: Video Recording – IPI reduced by 23.5% [cid:image001.png@01D0DF7D.01A745B0] Case 2: Browsing and Audio(Background) – IPI reduced by 33.11% [cid:image002.png@01D0DF7D.01A745B0]
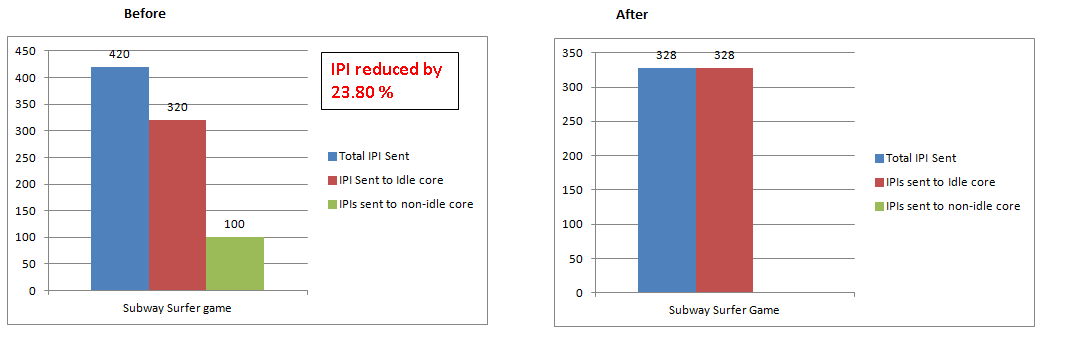
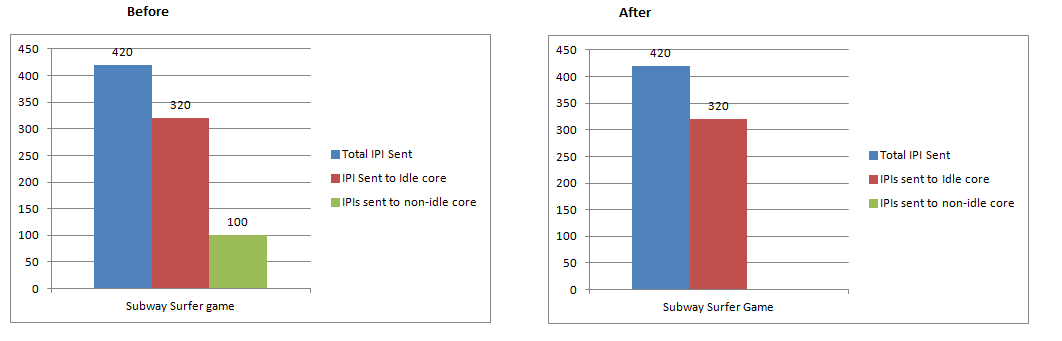
Case 3: Subway Surfer game – IPI reduced by 23.80%
[cid:image003.png@01D0DF7D.01A745B0] Thanks, Rahul Khandelwal
From: Sarbojit Ganguly [mailto:ganguly.s@samsung.com] Sent: 25 August 2015 17:47 To: Rahul Khandelwal (Rahul Khandelwal); Unixman Linuxboy; Jon Medhurst (Tixy); hiren.gajjar@samsung.com Cc: khilman@linaro.org; Morten.Rasmussen@arm.com; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com; Patrick Bellasi; Alex.Shi@linaro.org; Sarbojit Ganguly; SHARAN ALLUR Subject: Re: RE: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Hello Rahul,
Thanks for the metrics. I think there is some problem with the numbers. After we rule out 196 counts of IPI, the total IPI count should also get modified, isn't it?
Regards,
Sarbojit
------- Original Message -------
Sender : Rahul Khandelwal (Rahul Khandelwal)<Rahul.Khandelwal@spreadtrum.commailto:Rahul.Khandelwal@spreadtrum.com>
Date : Aug 25, 2015 17:23 (GMT+05:30)
Title : RE: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Dear All,
On an average we are saving around 25% of the IPIs sent to big domain CPUs. Following are the performance analysis in different cases :
Case 1: Video Recording – IPI reduced by 23.5%
[cid:image004.png@01D0DF7D.01A745B0]
IPI reduced by 23.5 % [cid:image005.png@01D0DF7D.01A745B0] Case 2: Browsing and Audio(Background) – IPI reduced by 33.11%
[cid:image006.png@01D0DF7D.01A745B0]
IPI reduced by 33.11 %
[cid:image007.png@01D0DF7D.01A745B0]
Case 3: Subway Surfer game – IPI reduced by 23.80%
[cid:image008.png@01D0DF7D.01A745B0] Thanks, Rahul Khandelwal
From: Unixman Linuxboy [mailto:unixman.linuxboy@gmail.com] Sent: 24 August 2015 18:23 To: Jon Medhurst (Tixy) Cc: khilman@linaro.orgmailto:khilman@linaro.org; Morten.Rasmussen@arm.commailto:Morten.Rasmussen@arm.com; vincent.guittot@linaro.orgmailto:vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.orgmailto:linaro-kernel@lists.linaro.org; Rahul Khandelwal (Rahul Khandelwal); Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.commailto:chris.redpath@arm.com; Patrick Bellasi; Alex.Shi@linaro.orgmailto:Alex.Shi@linaro.org; ganguly.s@samsung.commailto:ganguly.s@samsung.com; sharan.allur@samsung.commailto:sharan.allur@samsung.com Subject: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
On 19 Aug 2015 17:58, "Jon Medhurst (Tixy)" <tixy@linaro.orgmailto:tixy@linaro.org> wrote:
Adding Patrick Bellasi to the 'to' list as he's been working on HMP with Chris Redpath....
On Wed, 2015-08-19 at 05:18 +0000, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear All,
Please consider the patch, It is related to HMP force up migration. It will avoid sending of unnecessary interrupts to CPUs of faster domain hence increase performance.
From 2d48749ac30a2c0a2ef77132f303d69605c3dd3f Mon Sep 17 00:00:00 2001 From: rahulkhandelwal <rahul.khandelwal@spreadtrum.commailto:rahul.khandelwal@spreadtrum.com> Date: Fri, 14 Aug 2015 16:36:17 +0800 Subject: [PATCH 1/1] HMP: Do not send IPI if core already waked up
It is possible that we are sending IPI to a cpu in faster domain which is already waked up by other CPU in smaller domain.
HMP select the idle CPU using hmp_domain_min_load. Based on that HMP send IPI to the idle cpu in faster domain. There could be some latency by the core to wake up and set wake_for_idle_pull = 0. Next smaller cpu again check for idle CPU in faster domain and send IPI to already waked up CPU.
For example: In Octacore system, 0-3 are slower CPUs and 4-7 are faster CPUs. CPU0 and CPU1 has heavy tasks and CPU4 is idle. CPU0 execute hmp_force_up_migration find CPU4 as idle, it send IPI to CPU4 and return. After that CPU1 got the chance to run hmp_force_up_migration, it again find CPU4 as idle, send IPI to CPU4, which is not required.
Signed-off-by: rahulkhandelwal <rahul.khandelwal@spreadtrum.commailto:rahul.khandelwal@spreadtrum.com>
kernel/sched/fair.c | 5 +++++ 1 file changed, 5 insertions(+)
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c index 1baf641..388836c 100644 --- a/kernel/sched/fair.c +++ b/kernel/sched/fair.c @@ -7200,6 +7200,11 @@ static void hmp_force_up_migration(int this_cpu) } p = task_of(curr); if (hmp_up_migration(cpu, &target_cpu, curr)) {
if (cpu_rq(target_cpu)->wake_for_idle_pull == 1) {raw_spin_unlock_irqrestore(&target->lock, flags);spin_unlock(&hmp_force_migration);return;} cpu_rq(target_cpu)->wake_for_idle_pull = 1; raw_spin_unlock_irqrestore(&target->lock, flags); spin_unlock(&hmp_force_migration);
Can you please share the actual performance numbers gained by this patch?
-- 1.7.9.5
linaro-kernel mailing list linaro-kernel@lists.linaro.orgmailto:linaro-kernel@lists.linaro.org https://lists.linaro.org/mailman/listinfo/linaro-kernel
감사합니다
사보짓 선임 삼성 전자
----------------------------------------------------------------------+
The Tao lies beyond Yin and Yang. It is silent and still as a pool of water. |
It does not seek fame, therefore nobody knows its presence. |
It does not seek fortune, for it is complete within itself. |
It exists beyond space and time. |
----------------------------------------------------------------------+
[cid:image009.gif@01D0DF7D.01A745B0]
[http://ext.samsung.net/mailcheck/SeenTimeChecker?do=664566a9d0d36222d0e08742...]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

On 25/08/15 16:58, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Sarbojit,
Agreed with your point, thanks for raising it..
There was one issue in the total no of interrupt count in the previous chart preparation, actually the total no of interrupt is equal to the interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big domain CPUs. I just updated the below mentioned chart with the related data.
I would argue that a reduction on the total number of IPIs is not a suitable metric to evaluate the real impact on "application performance".
*Case 1: *
*Video Recording – IPI reduced by 23.5%*
*Case 2:*
Browsing and Audio(Background) – IPI reduced by 33.11%**Case 3: *
Subway Surfer game – IPI reduced by 23.80%*
All these use cases should produce an application specific performance metric, e.g. average frame rate or frame encoding time. I understand that it could be tricky to identify such a metric, however if we can measure the impact of the propose patch on application specific metrics the evaluation will be much more complete.
For example, it would be really nice to verify that the propose patch (with the integration into hmp_up_migration) could produce a sensible reduction on the responsiveness of the scheduler to migrate all the new-big tasks to big CPUs.
If possible, it is of interest a measure of the energy consumption required to complete a use-case, with and without the patch. Indeed, usually we like to evaluate HMP modifications in such a way to avoid sensible regressions in terms of power/performance figures.
Cheers Patrick

Seems it is big saving...
On 08/25/2015 11:58 PM, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Sarbojit,
Agreed with your point, thanks for raising it..
There was one issue in the total no of interrupt count in the previous chart preparation, actually the total no of interrupt is equal to the interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big domain CPUs. I just updated the below mentioned chart with the related data.
linaro-kernel@lists.linaro.org
-
 Alex Shi
Alex Shi -
 Patrick Bellasi
Patrick Bellasi -
 Rahul Khandelwal (Rahul Khandelwal)
Rahul Khandelwal (Rahul Khandelwal)