
Rahul,
I will run hackbench with your patch and share the results. Lets see if we can get some measurable differences on the performance side.
Regards, Sarbojit
------- Original Message ------- Sender : Alex Shialex.shi@linaro.org Date : Aug 28, 2015 12:25 (GMT+05:30) Title : Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Seems it is big saving...
On 08/25/2015 11:58 PM, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Sarbojit,
Agreed with your point, thanks for raising it..
There was one issue in the total no of interrupt count in the previous chart preparation, actually the total no of interrupt is equal to the interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big domain CPUs. I just updated the below mentioned chart with the related data.
????? ??? ?? ?? ?? ----------------------------------------------------------------------+ The Tao lies beyond Yin and Yang. It is silent and still as a pool of water. | It does not seek fame, therefore nobody knows its presence. | It does not seek fortune, for it is complete within itself. | It exists beyond space and time. | ----------------------------------------------------------------------+

Dear All,
We further checked with some modifications in the code while making the decision for up migration.
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU,
We now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
We checked for the performance of this patch with the hackbench tool.
Results for 10 samples are;
Without patch
maximum time of execution 3.342secs minimum time of execution 3.313secs
average of 10 samples: 3.368secs
With patch
maximum time of execution 3.319secs minimum time of execution 3.071secs
average of 10 samples: 3.169secs
On an average with this patch we would have performance improvement of 5.90%.
This would essentially lead to have better responsiveness of scheduler to migrate the big tasks to big CPUs.
---------------------------------------------------------------------------------------------------------------------------------
From e1df1fc8f069aafc592b42bc3fcc7780f32048a7 Mon Sep 17 00:00:00 2001
From: rahulkhandelwal rahul.khandelwal@spreadtrum.com Date: Sat, 5 Sep 2015 01:35:23 +0800 Subject: [PATCH 1/1] HMP: send IPI to all available big idle CPUs till their exist any heavy task on slower domain CPUs
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU, we now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
CC: Sanjeev Yadav sanjeev.yadav@spreadtrum.com CC: Gaurav Jindal gaurav.jindal@spreadtrum.com CC: sprd-ind-kernel-group@googlegroups.com Signed-off-by: rahulkhandelwal rahul.khandelwal@spreadtrum.com --- kernel/sched/fair.c | 188 ++++++++++++++++++++++++++++++++++++++++++--------- 1 file changed, 155 insertions(+), 33 deletions(-)
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c index 1baf641..a81ad6c 100644 --- a/kernel/sched/fair.c +++ b/kernel/sched/fair.c @@ -7156,6 +7156,34 @@ out: put_task_struct(p); }
+/* + * Update idle cpu for hmp_domain(faster or slower) + * Return 1 for Success(found idle cpu) otherwise 0 + */ + +static inline unsigned int hmp_domain_idle_cpu(struct hmp_domain *hmpd, + *idle_cpu, struct cpumask *affinity) +{ + int cpu; + unsigned long contrib; + struct sched_avg *avg; + struct cpumask temp_cpumask; + + cpumask_and(&temp_cpumask, &hmpd->cpus, affinity ? affinity : cpu_online_mask); + + for_each_cpu_mask(cpu, temp_cpumask) { + avg = &cpu_rq(cpu)->avg; + contrib = avg->load_avg_ratio; + if (!contrib && !cpu_rq(cpu)->wake_for_idle_pull) { + if (idle_cpu) + *idle_cpu = cpu; + return 1; + } + } + return 0; +} + + static DEFINE_SPINLOCK(hmp_force_migration);
/* @@ -7164,23 +7192,125 @@ static DEFINE_SPINLOCK(hmp_force_migration); */ static void hmp_force_up_migration(int this_cpu) { - int cpu, target_cpu; + int cpu; + int target_cpu = NR_CPUS; struct sched_entity *curr, *orig; - struct rq *target; unsigned long flags; unsigned int force, got_target; struct task_struct *p; + struct cpumask idle_cpus = {0}; + struct sched_avg *avg; + struct sched_entity *se; + struct rq *rq; + int nr_count;
- if (!spin_trylock(&hmp_force_migration)) + struct cpumask *hmp_slowcpu_mask = NULL; + struct cpumask *hmp_fastcpu_mask = NULL; + u64 now; + + if (!spin_trylock(&hmp_force_migration)) return; - for_each_online_cpu(cpu) { + + if(hmp_cpu_is_slowest(this_cpu)) { + hmp_fastcpu_mask = &hmp_faster_domain(this_cpu)->cpus; + hmp_slowcpu_mask = &hmp_cpu_domain(this_cpu)->cpus; + } + else { + hmp_fastcpu_mask = &hmp_cpu_domain(this_cpu)->cpus; + hmp_slowcpu_mask = &hmp_slower_domain(this_cpu)->cpus; + } + + /* Check for idle_cpus in faster domain, */ + /* update the idle mask if load_avg_ratio = 0 */ + for_each_cpu(cpu, hmp_fastcpu_mask) { + rq = cpu_rq(cpu); + avg = &cpu_rq(cpu)->avg; + if(avg->load_avg_ratio == 0) + cpumask_set_cpu(cpu, &idle_cpus); + } + + /* Don't iterate for slower domain, if no idle cpu in faster domain*/ + if(cpumask_empty(&idle_cpus)) + goto DOWN; + + /* Iterate slower domain cpus for up migration*/ + for_each_cpu(cpu, hmp_slowcpu_mask) { + if(!cpu_online(cpu)) { + continue; + } + + nr_count = hmp_max_tasks; + rq = cpu_rq(cpu); + + raw_spin_lock_irqsave(&rq->lock, flags); + + curr = rq->cfs.curr; + if (!curr || rq->active_balance) { + raw_spin_unlock_irqrestore(&rq->lock, flags); + continue; + } + if (!entity_is_task(curr)) { + struct cfs_rq *cfs_rq; + cfs_rq = group_cfs_rq(curr); + while (cfs_rq) { + curr = cfs_rq->curr; + cfs_rq = group_cfs_rq(curr); + } + } + + /* The currently running task is not on the runqueue */ + se = __pick_first_entity(cfs_rq_of(curr)); + while(!cpumask_empty(&idle_cpus) && nr_count-- && se) { + struct task_struct *p = task_of(se); + /* Check for eligible task for up migration */ + if (entity_is_task(se) && + se->avg.load_avg_ratio > hmp_up_threshold && + cpumask_intersects(hmp_fastcpu_mask, tsk_cpus_allowed(p))) { + +#ifdef CONFIG_SCHED_HMP_PRIO_FILTER + /* Filter by task priority */ + if (p->prio >= hmp_up_prio) { + se = __pick_next_entity(se); + continue; + } +#endif + + /* Let the task load settle before doing another up migration */ + /* hack - always use clock from first online CPU */ + now = cpu_rq(cpumask_first(cpu_online_mask))->clock_task; + if (((now - se->avg.hmp_last_up_migration) >> 10) + < hmp_next_up_threshold) { + se = __pick_next_entity(se); + continue; + } + + /* Wakeup for eligible idle cpu in faster domain */ + if (hmp_domain_idle_cpu(hmp_faster_domain(cpu), &target_cpu, + tsk_cpus_allowed(p))) { + cpu_rq(target_cpu)->wake_for_idle_pull = 1; + cpumask_clear_cpu(target_cpu, &idle_cpus); /* Update idle cpumask */ + smp_send_reschedule(target_cpu); + } + } + se = __pick_next_entity(se); + } + raw_spin_unlock_irqrestore(&rq->lock, flags); + } + +DOWN: + + for_each_cpu(cpu, hmp_fastcpu_mask) { + if(!cpu_online(cpu)) + continue; force = 0; got_target = 0; - target = cpu_rq(cpu); - raw_spin_lock_irqsave(&target->lock, flags); - curr = target->cfs.curr; - if (!curr || target->active_balance) { - raw_spin_unlock_irqrestore(&target->lock, flags); + rq = cpu_rq(cpu); + + raw_spin_lock_irqsave(&rq->lock, flags); + + curr = rq->cfs.curr; + if (!curr || rq->active_balance) { + raw_spin_unlock_irqrestore(&rq->lock, flags); continue; } if (!entity_is_task(curr)) { @@ -7193,19 +7323,7 @@ static void hmp_force_up_migration(int this_cpu) } } orig = curr; - curr = hmp_get_heaviest_task(curr, -1); - if (!curr) { - raw_spin_unlock_irqrestore(&target->lock, flags); - continue; - } - p = task_of(curr); - if (hmp_up_migration(cpu, &target_cpu, curr)) { - cpu_rq(target_cpu)->wake_for_idle_pull = 1; - raw_spin_unlock_irqrestore(&target->lock, flags); - spin_unlock(&hmp_force_migration); - smp_send_reschedule(target_cpu); - return; - } + if (!got_target) { /* * For now we just check the currently running task. @@ -7214,13 +7332,13 @@ static void hmp_force_up_migration(int this_cpu) */ curr = hmp_get_lightest_task(orig, 1); p = task_of(curr); - target->push_cpu = hmp_offload_down(cpu, curr); - if (target->push_cpu < NR_CPUS) { + rq->push_cpu = hmp_offload_down(cpu, curr); + if (rq->push_cpu < NR_CPUS) { get_task_struct(p); - target->migrate_task = p; + rq->migrate_task = p; got_target = 1; - trace_sched_hmp_migrate(p, target->push_cpu, HMP_MIGRATE_OFFLOAD); - hmp_next_down_delay(&p->se, target->push_cpu); + trace_sched_hmp_migrate(p, rq->push_cpu, HMP_MIGRATE_OFFLOAD); + hmp_next_down_delay(&p->se, rq->push_cpu); } } /* @@ -7229,24 +7347,28 @@ static void hmp_force_up_migration(int this_cpu) * CPU stopper take care of it. */ if (got_target) { - if (!task_running(target, p)) { + if (!task_running(rq, p)) { trace_sched_hmp_migrate_force_running(p, 0); - hmp_migrate_runnable_task(target); + hmp_migrate_runnable_task(rq); } else { - target->active_balance = 1; + rq->active_balance = 1; force = 1; } }
- raw_spin_unlock_irqrestore(&target->lock, flags); + raw_spin_unlock_irqrestore(&rq->lock, flags);
if (force) - stop_one_cpu_nowait(cpu_of(target), + stop_one_cpu_nowait(cpu_of(rq), hmp_active_task_migration_cpu_stop, - target, &target->active_balance_work); + rq, &rq->active_balance_work); } + + spin_unlock(&hmp_force_migration); + } + /* * hmp_idle_pull looks at little domain runqueues to see * if a task should be pulled.
Dear Patrick and Alex,
This is with reference to further performance/responsiveness testing of the patch dated September 04, 2015.
The patch intended to focus on 3 major areas in hmp_force_up_migration 1. CPU Run queue spin lock duration. 2. Heavy task migration on IDLE CPU in faster domain 3. Eliminating the fake IPI to big CPUs.
We are sharing the results for further testing of the patch.
Following are the test results for:
1. Running camera for 50 seconds. Here we are observing the load behaviour of camera related threads.
[cid:image001.png@01D0F177.25A30FB0]
2. Running browser with web page having images. we are observing the load behaviour of browser related and display related threads.
[cid:image002.png@01D0F177.25A30FB0]
3. We checked the time for which run queue is kept locked. With the patch proposed, "the locking period is reduced considerably as compared to original" code behavior.
Analysis for the results:
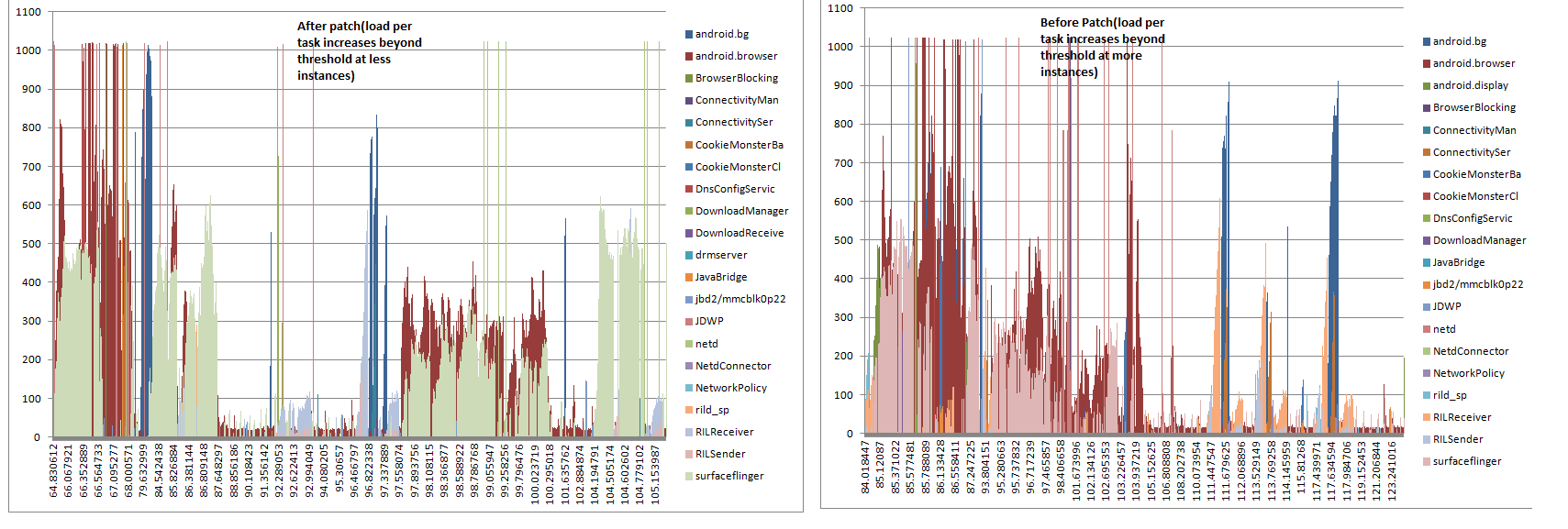
1. In the patch, the time for which runqueue is locked, has been reduced during up migration, "runqueue for faster cpu domain should not be kept locked which is the case with current code and vice versa. The suggested changes would lead to more execution chance for a task on its CPU and thereby preventing the load to get heavy"
2. In complex scenarios, where the load on slower domain CPUs increases above threshold, IPI are sent to big CPUs thereby increasing the responsiveness of the scheduler to migrate the heavy tasks.
3. With the proposed patch , no false IPI would be sent thereby preventing the fake wake ups of big CPUs.
Therefore, the proposed modification in HMP would help to achieve better performance and increase CPU responsiveness as load per task would be more stable (with the analysis point:1), and in case where the load increases beyond threshold, it would be more prompt to move such tasks to big CPUs without causing fake wake ups.
Thanks & Regards,
Rahul Khandelwal
-----Original Message----- From: Rahul Khandelwal (Rahul Khandelwal) Sent: 04 September 2015 23:11 To: 'ganguly.s@samsung.com'; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten.Rasmussen@arm.com; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: RE: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Dear All,
We further checked with some modifications in the code while making the decision for up migration.
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU,
We now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
We checked for the performance of this patch with the hackbench tool.
Results for 10 samples are;
Without patch
maximum time of execution 3.342secs
minimum time of execution 3.313secs
average of 10 samples: 3.368secs
With patch
maximum time of execution 3.319secs
minimum time of execution 3.071secs
average of 10 samples: 3.169secs
On an average with this patch we would have performance improvement of 5.90%.
This would essentially lead to have better responsiveness of scheduler to migrate the big tasks to big CPUs.
---------------------------------------------------------------------------------------------------------------------------------
From e1df1fc8f069aafc592b42bc3fcc7780f32048a7 Mon Sep 17 00:00:00 2001
From: rahulkhandelwal <rahul.khandelwal@spreadtrum.commailto:rahul.khandelwal@spreadtrum.com>
Date: Sat, 5 Sep 2015 01:35:23 +0800
Subject: [PATCH 1/1] HMP: send IPI to all available big idle CPUs till their exist any heavy task on slower domain CPUs
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU, we now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
CC: Sanjeev Yadav <sanjeev.yadav@spreadtrum.commailto:sanjeev.yadav@spreadtrum.com>
CC: Gaurav Jindal <gaurav.jindal@spreadtrum.commailto:gaurav.jindal@spreadtrum.com>
CC: sprd-ind-kernel-group@googlegroups.commailto:sprd-ind-kernel-group@googlegroups.com
Signed-off-by: rahulkhandelwal <rahul.khandelwal@spreadtrum.commailto:rahul.khandelwal@spreadtrum.com>
---
kernel/sched/fair.c | 188 ++++++++++++++++++++++++++++++++++++++++++---------
1 file changed, 155 insertions(+), 33 deletions(-)
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c index 1baf641..a81ad6c 100644
--- a/kernel/sched/fair.c
+++ b/kernel/sched/fair.c
@@ -7156,6 +7156,34 @@ out:
put_task_struct(p);
}
+/*
+ * Update idle cpu for hmp_domain(faster or slower)
+ * Return 1 for Success(found idle cpu) otherwise 0
+ */
+
+static inline unsigned int hmp_domain_idle_cpu(struct hmp_domain *hmpd,
+ *idle_cpu, struct cpumask *affinity) {
+ int cpu;
+ unsigned long contrib;
+ struct sched_avg *avg;
+ struct cpumask temp_cpumask;
+
+ cpumask_and(&temp_cpumask, &hmpd->cpus, affinity ? affinity :
+cpu_online_mask);
+
+ for_each_cpu_mask(cpu, temp_cpumask) {
+ avg = &cpu_rq(cpu)->avg;
+ contrib = avg->load_avg_ratio;
+ if (!contrib && !cpu_rq(cpu)->wake_for_idle_pull) {
+ if (idle_cpu)
+ *idle_cpu = cpu;
+ return 1;
+ }
+ }
+ return 0;
+}
+
+
static DEFINE_SPINLOCK(hmp_force_migration);
/*
@@ -7164,23 +7192,125 @@ static DEFINE_SPINLOCK(hmp_force_migration);
*/
static void hmp_force_up_migration(int this_cpu) {
- int cpu, target_cpu;
+ int cpu;
+ int target_cpu = NR_CPUS;
struct sched_entity *curr, *orig;
- struct rq *target;
unsigned long flags;
unsigned int force, got_target;
struct task_struct *p;
+ struct cpumask idle_cpus = {0};
+ struct sched_avg *avg;
+ struct sched_entity *se;
+ struct rq *rq;
+ int nr_count;
- if (!spin_trylock(&hmp_force_migration))
+ struct cpumask *hmp_slowcpu_mask = NULL;
+ struct cpumask *hmp_fastcpu_mask = NULL;
+ u64 now;
+
+ if (!spin_trylock(&hmp_force_migration))
return;
- for_each_online_cpu(cpu) {
+
+ if(hmp_cpu_is_slowest(this_cpu)) {
+ hmp_fastcpu_mask = &hmp_faster_domain(this_cpu)->cpus;
+ hmp_slowcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;
+ }
+ else {
+ hmp_fastcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;
+ hmp_slowcpu_mask = &hmp_slower_domain(this_cpu)->cpus;
+ }
+
+ /* Check for idle_cpus in faster domain, */
+ /* update the idle mask if load_avg_ratio = 0 */
+ for_each_cpu(cpu, hmp_fastcpu_mask) {
+ rq = cpu_rq(cpu);
+ avg = &cpu_rq(cpu)->avg;
+ if(avg->load_avg_ratio == 0)
+ cpumask_set_cpu(cpu, &idle_cpus);
+ }
+
+ /* Don't iterate for slower domain, if no idle cpu in faster domain*/
+ if(cpumask_empty(&idle_cpus))
+ goto DOWN;
+
+ /* Iterate slower domain cpus for up migration*/
+ for_each_cpu(cpu, hmp_slowcpu_mask) {
+ if(!cpu_online(cpu)) {
+ continue;
+ }
+
+ nr_count = hmp_max_tasks;
+ rq = cpu_rq(cpu);
+
+ raw_spin_lock_irqsave(&rq->lock, flags);
+
+ curr = rq->cfs.curr;
+ if (!curr || rq->active_balance) {
+ raw_spin_unlock_irqrestore(&rq->lock, flags);
+ continue;
+ }
+ if (!entity_is_task(curr)) {
+ struct cfs_rq *cfs_rq;
+ cfs_rq = group_cfs_rq(curr);
+ while (cfs_rq) {
+ curr = cfs_rq->curr;
+ cfs_rq = group_cfs_rq(curr);
+ }
+ }
+
+ /* The currently running task is not on the runqueue */
+ se = __pick_first_entity(cfs_rq_of(curr));
+ while(!cpumask_empty(&idle_cpus) && nr_count-- && se) {
+ struct task_struct *p = task_of(se);
+ /* Check for eligible task for up migration */
+ if (entity_is_task(se) &&
+ se->avg.load_avg_ratio > hmp_up_threshold &&
+ cpumask_intersects(hmp_fastcpu_mask, tsk_cpus_allowed(p))) {
+
+#ifdef CONFIG_SCHED_HMP_PRIO_FILTER
+ /* Filter by task priority */
+ if (p->prio >= hmp_up_prio) {
+ se = __pick_next_entity(se);
+ continue;
+ }
+#endif
+
+ /* Let the task load settle before doing another up migration */
+ /* hack - always use clock from first online CPU */
+ now = cpu_rq(cpumask_first(cpu_online_mask))->clock_task;
+ if (((now - se->avg.hmp_last_up_migration) >> 10)
+ < hmp_next_up_threshold) {
+ se = __pick_next_entity(se);
+ continue;
+ }
+
+ /* Wakeup for eligible idle cpu in faster domain */
+ if (hmp_domain_idle_cpu(hmp_faster_domain(cpu), &target_cpu,
+ tsk_cpus_allowed(p))) {
+ cpu_rq(target_cpu)->wake_for_idle_pull = 1;
+ cpumask_clear_cpu(target_cpu, &idle_cpus); /* Update idle cpumask */
+ smp_send_reschedule(target_cpu);
+ }
+ }
+ se = __pick_next_entity(se);
+ }
+ raw_spin_unlock_irqrestore(&rq->lock, flags);
+ }
+
+DOWN:
+
+ for_each_cpu(cpu, hmp_fastcpu_mask) {
+ if(!cpu_online(cpu))
+ continue;
force = 0;
got_target = 0;
- target = cpu_rq(cpu);
- raw_spin_lock_irqsave(&target->lock, flags);
- curr = target->cfs.curr;
- if (!curr || target->active_balance) {
- raw_spin_unlock_irqrestore(&target->lock, flags);
+ rq = cpu_rq(cpu);
+
+ raw_spin_lock_irqsave(&rq->lock, flags);
+
+ curr = rq->cfs.curr;
+ if (!curr || rq->active_balance) {
+ raw_spin_unlock_irqrestore(&rq->lock, flags);
continue;
}
if (!entity_is_task(curr)) {
@@ -7193,19 +7323,7 @@ static void hmp_force_up_migration(int this_cpu)
}
}
orig = curr;
- curr = hmp_get_heaviest_task(curr, -1);
- if (!curr) {
- raw_spin_unlock_irqrestore(&target->lock, flags);
- continue;
- }
- p = task_of(curr);
- if (hmp_up_migration(cpu, &target_cpu, curr)) {
- cpu_rq(target_cpu)->wake_for_idle_pull = 1;
- raw_spin_unlock_irqrestore(&target->lock, flags);
- spin_unlock(&hmp_force_migration);
- smp_send_reschedule(target_cpu);
- return;
- }
+
if (!got_target) {
/*
* For now we just check the currently running task.
@@ -7214,13 +7332,13 @@ static void hmp_force_up_migration(int this_cpu)
*/
curr = hmp_get_lightest_task(orig, 1);
p = task_of(curr);
- target->push_cpu = hmp_offload_down(cpu, curr);
- if (target->push_cpu < NR_CPUS) {
+ rq->push_cpu = hmp_offload_down(cpu, curr);
+ if (rq->push_cpu < NR_CPUS) {
get_task_struct(p);
- target->migrate_task = p;
+ rq->migrate_task = p;
got_target = 1;
- trace_sched_hmp_migrate(p, target->push_cpu, HMP_MIGRATE_OFFLOAD);
- hmp_next_down_delay(&p->se, target->push_cpu);
+ trace_sched_hmp_migrate(p, rq->push_cpu, HMP_MIGRATE_OFFLOAD);
+ hmp_next_down_delay(&p->se, rq->push_cpu);
}
}
/*
@@ -7229,24 +7347,28 @@ static void hmp_force_up_migration(int this_cpu)
* CPU stopper take care of it.
*/
if (got_target) {
- if (!task_running(target, p)) {
+ if (!task_running(rq, p)) {
trace_sched_hmp_migrate_force_running(p, 0);
- hmp_migrate_runnable_task(target);
+ hmp_migrate_runnable_task(rq);
} else {
- target->active_balance = 1;
+ rq->active_balance = 1;
force = 1;
}
}
- raw_spin_unlock_irqrestore(&target->lock, flags);
+ raw_spin_unlock_irqrestore(&rq->lock, flags);
if (force)
- stop_one_cpu_nowait(cpu_of(target),
+ stop_one_cpu_nowait(cpu_of(rq),
hmp_active_task_migration_cpu_stop,
- target, &target->active_balance_work);
+ rq, &rq->active_balance_work);
}
+
+
spin_unlock(&hmp_force_migration);
+
}
+
/*
* hmp_idle_pull looks at little domain runqueues to see
* if a task should be pulled.
--
1.7.9.5
---------------------------------------------------------------------------------------------------------------
-----Original Message-----
From: Sarbojit Ganguly [mailto:ganguly.s@samsung.com]
Sent: 04 September 2015 08:46
To: Alex Shi; Rahul Khandelwal (Rahul Khandelwal); Sarbojit Ganguly; Jon Medhurst (Tixy)
Cc: Hiren Bharatbhai Gajjar; khilman@linaro.orgmailto:khilman@linaro.org; Morten.Rasmussen@arm.commailto:Morten.Rasmussen@arm.com; vincent.guittot@linaro.orgmailto:vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.orgmailto:linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.commailto:chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI
Subject: Re: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Rahul,
I will run hackbench with your patch and share the results. Lets see if we can get some measurable differences on the performance side.
Regards,
Sarbojit
------- Original Message -------
Sender : Alex Shi<alex.shi@linaro.orgmailto:alex.shi@linaro.org>
Date : Aug 28, 2015 12:25 (GMT+05:30)
Title : Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Seems it is big saving...
On 08/25/2015 11:58 PM, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Sarbojit,
Agreed with your point, thanks for raising it..
There was one issue in the total no of interrupt count in the previous
chart preparation, actually the total no of interrupt is equal to the
interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big
domain CPUs. I just updated the below mentioned chart with the related data.
?????
??? ?? ?? ??
----------------------------------------------------------------------+
The Tao lies beyond Yin and Yang. It is silent and still as a pool of water. |
It does not seek fame, therefore nobody knows its presence. |
It does not seek fortune, for it is complete within itself. |
It exists beyond space and time. |
----------------------------------------------------------------------+
{kind=link}
{kind=link}

On 17/09/15 14:11, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Patrick and Alex,
Hi Rahul, thanks for the analysis you did.
The patch you are proposing seems interesting but it is also actually changing a lot in the active load balance path. Our evaluation strategy requires to run a complete set of performance and _power_ analysis.
Unfortunately right now I'm a bit busy on the EAS side but I would like to give a try to your patch in one of the following weeks.
Could you tell me on which kernel exactly is that patch to be applied?
Thanks Patrick
This is with reference to further performance/responsiveness testing of the patch dated September 04, 2015.
The patch intended to focus on 3 major areas in hmp_force_up_migration
CPU Run queue spin lock duration.
Heavy task migration on IDLE CPU in faster domain
Eliminating the fake IPI to big CPUs.
We are sharing the results for further testing of the patch.
Following are the test results for:
- Running camera for 50 seconds. Here we are observing the load
behaviour of camera related threads.
cid:image001.png@01D0F177.25A30FB0
- Running browser with web page having images. we are observing the
load behaviour of browser related and display related threads.
cid:image002.png@01D0F177.25A30FB0
- We checked the time for which run queue is kept locked. With the
patch proposed, “the locking period is reduced considerably as compared to original” code behavior.
Analysis for the results:
1.In the patch, the time for which runqueue is locked, has been reduced during up migration, “runqueue for faster cpu domain should not be kept locked which is the case with current code and vice versa. The suggested changes would lead to more execution chance for a task on its CPU and thereby preventing the load to get heavy”
2.In complex scenarios, where the load on slower domain CPUs increases above threshold, IPI are sent to big CPUs thereby increasing the responsiveness of the scheduler to migrate the heavy tasks.
3.With the proposed patch , no false IPI would be sent thereby preventing the fake wake ups of big CPUs.
Therefore, the proposed modification in HMP would help to achieve better performance and increase CPU responsiveness as load per task would be more stable (with the analysis point:1), and in case where the load increases beyond threshold, it would be more prompt to move such tasks to big CPUs without causing fake wake ups.
Thanks & Regards,
Rahul Khandelwal
-----Original Message----- From: Rahul Khandelwal (Rahul Khandelwal) Sent: 04 September 2015 23:11 To: 'ganguly.s@samsung.com'; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten.Rasmussen@arm.com; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: RE: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Dear All,
We further checked with some modifications in the code while making the decision for up migration.
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU,
We now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
We checked for the performance of this patch with the hackbench tool.
Results for 10 samples are;
Without patch
maximum time of execution 3.342secs
minimum time of execution 3.313secs
average of 10 samples: 3.368secs
With patch
maximum time of execution 3.319secs
minimum time of execution 3.071secs
average of 10 samples: 3.169secs
On an average with this patch we would have performance improvement of 5.90%.
This would essentially lead to have better responsiveness of scheduler to migrate the big tasks to big CPUs.
From e1df1fc8f069aafc592b42bc3fcc7780f32048a7 Mon Sep 17 00:00:00 2001
From: rahulkhandelwal <rahul.khandelwal@spreadtrum.com mailto:rahul.khandelwal@spreadtrum.com>
Date: Sat, 5 Sep 2015 01:35:23 +0800
Subject: [PATCH 1/1] HMP: send IPI to all available big idle CPUs till their exist any heavy task on slower domain CPUs
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU, we now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
CC: Sanjeev Yadav <sanjeev.yadav@spreadtrum.com mailto:sanjeev.yadav@spreadtrum.com>
CC: Gaurav Jindal <gaurav.jindal@spreadtrum.com mailto:gaurav.jindal@spreadtrum.com>
CC: sprd-ind-kernel-group@googlegroups.com mailto:sprd-ind-kernel-group@googlegroups.com
Signed-off-by: rahulkhandelwal <rahul.khandelwal@spreadtrum.com mailto:rahul.khandelwal@spreadtrum.com>
kernel/sched/fair.c | 188 ++++++++++++++++++++++++++++++++++++++++++---------
1 file changed, 155 insertions(+), 33 deletions(-)
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c index 1baf641..a81ad6c 100644
--- a/kernel/sched/fair.c
+++ b/kernel/sched/fair.c
@@ -7156,6 +7156,34 @@ out:
put_task_struct(p);}
+/*
- Update idle cpu for hmp_domain(faster or slower)
- Return 1 for Success(found idle cpu) otherwise 0
*/
+static inline unsigned int hmp_domain_idle_cpu(struct hmp_domain *hmpd,
*idle_cpu, struct cpumask *affinity) {int cpu;unsigned long contrib;struct sched_avg *avg;struct cpumask temp_cpumask;cpumask_and(&temp_cpumask, &hmpd->cpus, affinity ? affinity :+cpu_online_mask);
for_each_cpu_mask(cpu, temp_cpumask) {avg = &cpu_rq(cpu)->avg;contrib = avg->load_avg_ratio;if (!contrib && !cpu_rq(cpu)->wake_for_idle_pull) {if (idle_cpu)*idle_cpu = cpu;return 1;}}return 0;+}
static DEFINE_SPINLOCK(hmp_force_migration);
/*
@@ -7164,23 +7192,125 @@ static DEFINE_SPINLOCK(hmp_force_migration);
*/
static void hmp_force_up_migration(int this_cpu) {
int cpu, target_cpu;
int cpu;int target_cpu = NR_CPUS; struct sched_entity *curr, *orig;
struct rq *target; unsigned long flags; unsigned int force, got_target; struct task_struct *p;
struct cpumask idle_cpus = {0};struct sched_avg *avg;struct sched_entity *se;struct rq *rq;int nr_count;
if (!spin_trylock(&hmp_force_migration))
struct cpumask *hmp_slowcpu_mask = NULL;struct cpumask *hmp_fastcpu_mask = NULL;u64 now;if (!spin_trylock(&hmp_force_migration)) return;
for_each_online_cpu(cpu) {
if(hmp_cpu_is_slowest(this_cpu)) {hmp_fastcpu_mask = &hmp_faster_domain(this_cpu)->cpus;hmp_slowcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;}else {hmp_fastcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;hmp_slowcpu_mask = &hmp_slower_domain(this_cpu)->cpus;}/* Check for idle_cpus in faster domain, *//* update the idle mask if load_avg_ratio = 0 */for_each_cpu(cpu, hmp_fastcpu_mask) {rq = cpu_rq(cpu);avg = &cpu_rq(cpu)->avg;if(avg->load_avg_ratio == 0)cpumask_set_cpu(cpu, &idle_cpus);}/* Don't iterate for slower domain, if no idle cpu in faster domain*/if(cpumask_empty(&idle_cpus))goto DOWN;/* Iterate slower domain cpus for up migration*/for_each_cpu(cpu, hmp_slowcpu_mask) {if(!cpu_online(cpu)) {continue;}nr_count = hmp_max_tasks;rq = cpu_rq(cpu);raw_spin_lock_irqsave(&rq->lock, flags);curr = rq->cfs.curr;if (!curr || rq->active_balance) {raw_spin_unlock_irqrestore(&rq->lock, flags);continue;}if (!entity_is_task(curr)) {struct cfs_rq *cfs_rq;cfs_rq = group_cfs_rq(curr);while (cfs_rq) {curr = cfs_rq->curr;cfs_rq = group_cfs_rq(curr);}}/* The currently running task is not on the runqueue */se = __pick_first_entity(cfs_rq_of(curr));while(!cpumask_empty(&idle_cpus) && nr_count-- && se) {struct task_struct *p = task_of(se);/* Check for eligible task for up migration */if (entity_is_task(se) &&se->avg.load_avg_ratio > hmp_up_threshold &&cpumask_intersects(hmp_fastcpu_mask,tsk_cpus_allowed(p))) {
+#ifdef CONFIG_SCHED_HMP_PRIO_FILTER
/* Filter by task priority */if (p->prio >= hmp_up_prio) {se = __pick_next_entity(se);continue;}+#endif
/* Let the task load settle before doing anotherup migration */
/* hack - always use clock from first online CPU */now =cpu_rq(cpumask_first(cpu_online_mask))->clock_task;
if (((now - se->avg.hmp_last_up_migration) >> 10)< hmp_next_up_threshold) {se = __pick_next_entity(se);continue;}/* Wakeup for eligible idle cpu in faster domain */if (hmp_domain_idle_cpu(hmp_faster_domain(cpu),&target_cpu,
tsk_cpus_allowed(p))) {cpu_rq(target_cpu)->wake_for_idle_pull = 1;cpumask_clear_cpu(target_cpu, &idle_cpus);/* Update idle cpumask */
smp_send_reschedule(target_cpu);}}se = __pick_next_entity(se);}raw_spin_unlock_irqrestore(&rq->lock, flags);}+DOWN:
for_each_cpu(cpu, hmp_fastcpu_mask) {if(!cpu_online(cpu))continue; force = 0; got_target = 0;
target = cpu_rq(cpu);raw_spin_lock_irqsave(&target->lock, flags);curr = target->cfs.curr;if (!curr || target->active_balance) {raw_spin_unlock_irqrestore(&target->lock, flags);
rq = cpu_rq(cpu);raw_spin_lock_irqsave(&rq->lock, flags);curr = rq->cfs.curr;if (!curr || rq->active_balance) {raw_spin_unlock_irqrestore(&rq->lock, flags); continue; } if (!entity_is_task(curr)) {@@ -7193,19 +7323,7 @@ static void hmp_force_up_migration(int this_cpu)
} } orig = curr;
curr = hmp_get_heaviest_task(curr, -1);if (!curr) {raw_spin_unlock_irqrestore(&target->lock, flags);continue;}p = task_of(curr);if (hmp_up_migration(cpu, &target_cpu, curr)) {cpu_rq(target_cpu)->wake_for_idle_pull = 1;raw_spin_unlock_irqrestore(&target->lock, flags);spin_unlock(&hmp_force_migration);smp_send_reschedule(target_cpu);return;}
if (!got_target) { /* * For now we just check the currently running task.@@ -7214,13 +7332,13 @@ static void hmp_force_up_migration(int this_cpu)
*/ curr = hmp_get_lightest_task(orig, 1); p = task_of(curr);
target->push_cpu = hmp_offload_down(cpu, curr);if (target->push_cpu < NR_CPUS) {
rq->push_cpu = hmp_offload_down(cpu, curr);if (rq->push_cpu < NR_CPUS) { get_task_struct(p);
target->migrate_task = p;
rq->migrate_task = p; got_target = 1;
trace_sched_hmp_migrate(p, target->push_cpu,HMP_MIGRATE_OFFLOAD);
hmp_next_down_delay(&p->se, target->push_cpu);
trace_sched_hmp_migrate(p, rq->push_cpu,HMP_MIGRATE_OFFLOAD);
hmp_next_down_delay(&p->se, rq->push_cpu); } } /*@@ -7229,24 +7347,28 @@ static void hmp_force_up_migration(int this_cpu)
* CPU stopper take care of it. */ if (got_target) {
if (!task_running(target, p)) {
if (!task_running(rq, p)) { trace_sched_hmp_migrate_force_running(p, 0);
hmp_migrate_runnable_task(target);
hmp_migrate_runnable_task(rq); } else {
target->active_balance = 1;
rq->active_balance = 1; force = 1; } }
raw_spin_unlock_irqrestore(&target->lock, flags);
raw_spin_unlock_irqrestore(&rq->lock, flags); if (force)
stop_one_cpu_nowait(cpu_of(target),
stop_one_cpu_nowait(cpu_of(rq), hmp_active_task_migration_cpu_stop,
target, &target->active_balance_work);
rq, &rq->active_balance_work); }spin_unlock(&hmp_force_migration);}
/*
hmp_idle_pull looks at little domain runqueues to see
if a task should be pulled.
--
1.7.9.5
-----Original Message-----
From: Sarbojit Ganguly [mailto:ganguly.s@samsung.com]
Sent: 04 September 2015 08:46
To: Alex Shi; Rahul Khandelwal (Rahul Khandelwal); Sarbojit Ganguly; Jon Medhurst (Tixy)
Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org mailto:khilman@linaro.org; Morten.Rasmussen@arm.com mailto:Morten.Rasmussen@arm.com; vincent.guittot@linaro.org mailto:vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org mailto:linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com mailto:chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI
Subject: Re: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Rahul,
I will run hackbench with your patch and share the results. Lets see if we can get some measurable differences on the performance side.
Regards,
Sarbojit
------- Original Message -------
Sender : Alex Shi<alex.shi@linaro.org mailto:alex.shi@linaro.org>
Date : Aug 28, 2015 12:25 (GMT+05:30)
Title : Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Seems it is big saving...
On 08/25/2015 11:58 PM, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Sarbojit,
Agreed with your point, thanks for raising it..
There was one issue in the total no of interrupt count in the previous
chart preparation, actually the total no of interrupt is equal to the
interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big
domain CPUs. I just updated the below mentioned chart with the
related data.
?????
??? ?? ?? ??
----------------------------------------------------------------------+
The Tao lies beyond Yin and Yang. It is silent and still as a pool of water. |
It does not seek fame, therefore nobody knows its presence. |
It does not seek fortune, for it is complete within itself. |
It exists beyond space and time. |
----------------------------------------------------------------------+
Dear Patrick,
We have tested our modification on kernel v3.10.
Thanks & Regards, Rahul Khandelwal
-----Original Message----- From: Patrick Bellasi [mailto:patrick.bellasi@arm.com] Sent: 17 September 2015 20:42 To: Rahul Khandelwal (Rahul Khandelwal); ganguly.s@samsung.com; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten Rasmussen; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); Chris Redpath; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
On 17/09/15 14:11, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Patrick and Alex,
Hi Rahul, thanks for the analysis you did.
The patch you are proposing seems interesting but it is also actually changing a lot in the active load balance path. Our evaluation strategy requires to run a complete set of performance and _power_ analysis.
Unfortunately right now I'm a bit busy on the EAS side but I would like to give a try to your patch in one of the following weeks.
Could you tell me on which kernel exactly is that patch to be applied?
Thanks Patrick
This is with reference to further performance/responsiveness testing of the patch dated September 04, 2015.
The patch intended to focus on 3 major areas in hmp_force_up_migration
CPU Run queue spin lock duration.
Heavy task migration on IDLE CPU in faster domain
Eliminating the fake IPI to big CPUs.
We are sharing the results for further testing of the patch.
Following are the test results for:
- Running camera for 50 seconds. Here we are observing the load
behaviour of camera related threads.
cid:image001.png@01D0F177.25A30FB0
- Running browser with web page having images. we are observing the
load behaviour of browser related and display related threads.
cid:image002.png@01D0F177.25A30FB0
- We checked the time for which run queue is kept locked. With the
patch proposed, "the locking period is reduced considerably as compared to original" code behavior.
Analysis for the results:
1.In the patch, the time for which runqueue is locked, has been reduced during up migration, "runqueue for faster cpu domain should not be kept locked which is the case with current code and vice versa. The suggested changes would lead to more execution chance for a task on its CPU and thereby preventing the load to get heavy"
2.In complex scenarios, where the load on slower domain CPUs increases above threshold, IPI are sent to big CPUs thereby increasing the responsiveness of the scheduler to migrate the heavy tasks.
3.With the proposed patch , no false IPI would be sent thereby preventing the fake wake ups of big CPUs.
Therefore, the proposed modification in HMP would help to achieve better performance and increase CPU responsiveness as load per task would be more stable (with the analysis point:1), and in case where the load increases beyond threshold, it would be more prompt to move such tasks to big CPUs without causing fake wake ups.
Thanks & Regards,
Rahul Khandelwal
-----Original Message----- From: Rahul Khandelwal (Rahul Khandelwal) Sent: 04 September 2015 23:11 To: 'ganguly.s@samsung.com'; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten.Rasmussen@arm.com; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: RE: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Dear All,
We further checked with some modifications in the code while making the decision for up migration.
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU,
We now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
We checked for the performance of this patch with the hackbench tool.
Results for 10 samples are;
Without patch
maximum time of execution 3.342secs
minimum time of execution 3.313secs
average of 10 samples: 3.368secs
With patch
maximum time of execution 3.319secs
minimum time of execution 3.071secs
average of 10 samples: 3.169secs
On an average with this patch we would have performance improvement of 5.90%.
This would essentially lead to have better responsiveness of scheduler to migrate the big tasks to big CPUs.
From e1df1fc8f069aafc592b42bc3fcc7780f32048a7 Mon Sep 17 00:00:00 2001
From: rahulkhandelwal <rahul.khandelwal@spreadtrum.com mailto:rahul.khandelwal@spreadtrum.com>
Date: Sat, 5 Sep 2015 01:35:23 +0800
Subject: [PATCH 1/1] HMP: send IPI to all available big idle CPUs till their exist any heavy task on slower domain CPUs
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU, we now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
CC: Sanjeev Yadav <sanjeev.yadav@spreadtrum.com mailto:sanjeev.yadav@spreadtrum.com>
CC: Gaurav Jindal <gaurav.jindal@spreadtrum.com mailto:gaurav.jindal@spreadtrum.com>
CC: sprd-ind-kernel-group@googlegroups.com mailto:sprd-ind-kernel-group@googlegroups.com
Signed-off-by: rahulkhandelwal <rahul.khandelwal@spreadtrum.com mailto:rahul.khandelwal@spreadtrum.com>
kernel/sched/fair.c | 188 ++++++++++++++++++++++++++++++++++++++++++---------
1 file changed, 155 insertions(+), 33 deletions(-)
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c index 1baf641..a81ad6c 100644
--- a/kernel/sched/fair.c
+++ b/kernel/sched/fair.c
@@ -7156,6 +7156,34 @@ out:
put_task_struct(p);}
+/*
- Update idle cpu for hmp_domain(faster or slower)
- Return 1 for Success(found idle cpu) otherwise 0
*/
+static inline unsigned int hmp_domain_idle_cpu(struct hmp_domain +*hmpd,
*idle_cpu, struct cpumask *affinity) {int cpu;unsigned long contrib;struct sched_avg *avg;struct cpumask temp_cpumask;cpumask_and(&temp_cpumask, &hmpd->cpus, affinity ? affinity :+cpu_online_mask);
for_each_cpu_mask(cpu, temp_cpumask) {avg = &cpu_rq(cpu)->avg;contrib = avg->load_avg_ratio;if (!contrib && !cpu_rq(cpu)->wake_for_idle_pull) {if (idle_cpu)*idle_cpu = cpu;return 1;}}return 0;+}
static DEFINE_SPINLOCK(hmp_force_migration);
/*
@@ -7164,23 +7192,125 @@ static DEFINE_SPINLOCK(hmp_force_migration);
*/
static void hmp_force_up_migration(int this_cpu) {
int cpu, target_cpu;
int cpu;int target_cpu = NR_CPUS; struct sched_entity *curr, *orig;
struct rq *target; unsigned long flags; unsigned int force, got_target; struct task_struct *p;
struct cpumask idle_cpus = {0};struct sched_avg *avg;struct sched_entity *se;struct rq *rq;int nr_count;
if (!spin_trylock(&hmp_force_migration))
struct cpumask *hmp_slowcpu_mask = NULL;struct cpumask *hmp_fastcpu_mask = NULL;u64 now;if (!spin_trylock(&hmp_force_migration)) return;
for_each_online_cpu(cpu) {
if(hmp_cpu_is_slowest(this_cpu)) {hmp_fastcpu_mask = &hmp_faster_domain(this_cpu)->cpus;hmp_slowcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;}else {hmp_fastcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;hmp_slowcpu_mask = &hmp_slower_domain(this_cpu)->cpus;}/* Check for idle_cpus in faster domain, *//* update the idle mask if load_avg_ratio = 0 */for_each_cpu(cpu, hmp_fastcpu_mask) {rq = cpu_rq(cpu);avg = &cpu_rq(cpu)->avg;if(avg->load_avg_ratio == 0)cpumask_set_cpu(cpu, &idle_cpus);}/* Don't iterate for slower domain, if no idle cpu in fasterdomain*/
if(cpumask_empty(&idle_cpus))goto DOWN;/* Iterate slower domain cpus for up migration*/for_each_cpu(cpu, hmp_slowcpu_mask) {if(!cpu_online(cpu)) {continue;}nr_count = hmp_max_tasks;rq = cpu_rq(cpu);raw_spin_lock_irqsave(&rq->lock, flags);curr = rq->cfs.curr;if (!curr || rq->active_balance) {raw_spin_unlock_irqrestore(&rq->lock, flags);continue;}if (!entity_is_task(curr)) {struct cfs_rq *cfs_rq;cfs_rq = group_cfs_rq(curr);while (cfs_rq) {curr = cfs_rq->curr;cfs_rq = group_cfs_rq(curr);}}/* The currently running task is not on the runqueue */se = __pick_first_entity(cfs_rq_of(curr));while(!cpumask_empty(&idle_cpus) && nr_count-- && se) {struct task_struct *p = task_of(se);/* Check for eligible task for up migration */if (entity_is_task(se) &&se->avg.load_avg_ratio > hmp_up_threshold &&cpumask_intersects(hmp_fastcpu_mask,tsk_cpus_allowed(p))) {
+#ifdef CONFIG_SCHED_HMP_PRIO_FILTER
/* Filter by task priority */if (p->prio >= hmp_up_prio) {se = __pick_next_entity(se);continue;}+#endif
/* Let the task load settle before doinganother
up migration */
/* hack - always use clock from first onlineCPU */
now =cpu_rq(cpumask_first(cpu_online_mask))->clock_task;
if (((now - se->avg.hmp_last_up_migration) >>
< hmp_next_up_threshold) {se = __pick_next_entity(se);continue;}/* Wakeup for eligible idle cpu in fasterdomain */
if(hmp_domain_idle_cpu(hmp_faster_domain(cpu),
&target_cpu,
tsk_cpus_allowed(p))) {cpu_rq(target_cpu)->wake_for_idle_pull =1;
cpumask_clear_cpu(target_cpu,&idle_cpus);
/* Update idle cpumask */
smp_send_reschedule(target_cpu);}}se = __pick_next_entity(se);}raw_spin_unlock_irqrestore(&rq->lock, flags);}+DOWN:
for_each_cpu(cpu, hmp_fastcpu_mask) {if(!cpu_online(cpu))continue; force = 0; got_target = 0;
target = cpu_rq(cpu);raw_spin_lock_irqsave(&target->lock, flags);curr = target->cfs.curr;if (!curr || target->active_balance) {raw_spin_unlock_irqrestore(&target->lock, flags);
rq = cpu_rq(cpu);raw_spin_lock_irqsave(&rq->lock, flags);curr = rq->cfs.curr;if (!curr || rq->active_balance) {raw_spin_unlock_irqrestore(&rq->lock, flags); continue; } if (!entity_is_task(curr)) {@@ -7193,19 +7323,7 @@ static void hmp_force_up_migration(int this_cpu)
} } orig = curr;
curr = hmp_get_heaviest_task(curr, -1);if (!curr) {raw_spin_unlock_irqrestore(&target->lock, flags);continue;}p = task_of(curr);if (hmp_up_migration(cpu, &target_cpu, curr)) {cpu_rq(target_cpu)->wake_for_idle_pull = 1;raw_spin_unlock_irqrestore(&target->lock, flags);spin_unlock(&hmp_force_migration);smp_send_reschedule(target_cpu);return;}
if (!got_target) { /* * For now we just check the currently running task.@@ -7214,13 +7332,13 @@ static void hmp_force_up_migration(int this_cpu)
*/ curr = hmp_get_lightest_task(orig, 1); p = task_of(curr);
target->push_cpu = hmp_offload_down(cpu, curr);if (target->push_cpu < NR_CPUS) {
rq->push_cpu = hmp_offload_down(cpu, curr);if (rq->push_cpu < NR_CPUS) { get_task_struct(p);
target->migrate_task = p;
rq->migrate_task = p; got_target = 1;
trace_sched_hmp_migrate(p, target->push_cpu,HMP_MIGRATE_OFFLOAD);
hmp_next_down_delay(&p->se, target->push_cpu);
trace_sched_hmp_migrate(p, rq->push_cpu,HMP_MIGRATE_OFFLOAD);
hmp_next_down_delay(&p->se, rq->push_cpu); } } /*@@ -7229,24 +7347,28 @@ static void hmp_force_up_migration(int this_cpu)
* CPU stopper take care of it. */ if (got_target) {
if (!task_running(target, p)) {
if (!task_running(rq, p)) { trace_sched_hmp_migrate_force_running(p, 0);
hmp_migrate_runnable_task(target);
hmp_migrate_runnable_task(rq); } else {
target->active_balance = 1;
rq->active_balance = 1; force = 1; } }
raw_spin_unlock_irqrestore(&target->lock, flags);
raw_spin_unlock_irqrestore(&rq->lock, flags); if (force)
stop_one_cpu_nowait(cpu_of(target),
stop_one_cpu_nowait(cpu_of(rq), hmp_active_task_migration_cpu_stop,
target, &target->active_balance_work);
rq, &rq->active_balance_work); }spin_unlock(&hmp_force_migration);}
/*
hmp_idle_pull looks at little domain runqueues to see
if a task should be pulled.
--
1.7.9.5
-----Original Message-----
From: Sarbojit Ganguly [mailto:ganguly.s@samsung.com]
Sent: 04 September 2015 08:46
To: Alex Shi; Rahul Khandelwal (Rahul Khandelwal); Sarbojit Ganguly; Jon Medhurst (Tixy)
Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org mailto:khilman@linaro.org; Morten.Rasmussen@arm.com mailto:Morten.Rasmussen@arm.com; vincent.guittot@linaro.org mailto:vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org mailto:linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com mailto:chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI
Subject: Re: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Rahul,
I will run hackbench with your patch and share the results. Lets see if we can get some measurable differences on the performance side.
Regards,
Sarbojit
------- Original Message -------
Sender : Alex Shi<alex.shi@linaro.org mailto:alex.shi@linaro.org>
Date : Aug 28, 2015 12:25 (GMT+05:30)
Title : Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Seems it is big saving...
On 08/25/2015 11:58 PM, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Sarbojit,
Agreed with your point, thanks for raising it..
There was one issue in the total no of interrupt count in the
previous
chart preparation, actually the total no of interrupt is equal to
the
interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big
domain CPUs. I just updated the below mentioned chart with the
related data.
?????
??? ?? ?? ??
----------------------------------------------------------------------+
The Tao lies beyond Yin and Yang. It is silent and still as a pool of water. |
It does not seek fame, therefore nobody knows its presence. |
It does not seek fortune, for it is complete within itself. |
It exists beyond space and time. |
----------------------------------------------------------------------+
-- #include <best/regards.h>
Patrick Bellasi
Hello Patrick,
I was wondering if you could process the HMP patch discussed in trailing mail and help forward it at next step.
Thanks for your help.
Regards, Rahul Khandelwal
-----Original Message----- From: Rahul Khandelwal (Rahul Khandelwal) Sent: 18 September 2015 10:48 To: 'Patrick Bellasi'; ganguly.s@samsung.com; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten Rasmussen; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); Chris Redpath; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: RE: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Dear Patrick,
We have tested our modification on kernel v3.10.
Thanks & Regards, Rahul Khandelwal
-----Original Message----- From: Patrick Bellasi [mailto:patrick.bellasi@arm.com] Sent: 17 September 2015 20:42 To: Rahul Khandelwal (Rahul Khandelwal); ganguly.s@samsung.com; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten Rasmussen; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); Chris Redpath; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
On 17/09/15 14:11, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Patrick and Alex,
Hi Rahul, thanks for the analysis you did.
The patch you are proposing seems interesting but it is also actually changing a lot in the active load balance path. Our evaluation strategy requires to run a complete set of performance and _power_ analysis.
Unfortunately right now I'm a bit busy on the EAS side but I would like to give a try to your patch in one of the following weeks.
Could you tell me on which kernel exactly is that patch to be applied?
Thanks Patrick
This is with reference to further performance/responsiveness testing of the patch dated September 04, 2015.
The patch intended to focus on 3 major areas in hmp_force_up_migration
CPU Run queue spin lock duration.
Heavy task migration on IDLE CPU in faster domain
Eliminating the fake IPI to big CPUs.
We are sharing the results for further testing of the patch.
Following are the test results for:
- Running camera for 50 seconds. Here we are observing the load
behaviour of camera related threads.
cid:image001.png@01D0F177.25A30FB0
- Running browser with web page having images. we are observing the
load behaviour of browser related and display related threads.
cid:image002.png@01D0F177.25A30FB0
- We checked the time for which run queue is kept locked. With the
patch proposed, "the locking period is reduced considerably as compared to original" code behavior.
Analysis for the results:
1.In the patch, the time for which runqueue is locked, has been reduced during up migration, "runqueue for faster cpu domain should not be kept locked which is the case with current code and vice versa. The suggested changes would lead to more execution chance for a task on its CPU and thereby preventing the load to get heavy"
2.In complex scenarios, where the load on slower domain CPUs increases above threshold, IPI are sent to big CPUs thereby increasing the responsiveness of the scheduler to migrate the heavy tasks.
3.With the proposed patch , no false IPI would be sent thereby preventing the fake wake ups of big CPUs.
Therefore, the proposed modification in HMP would help to achieve better performance and increase CPU responsiveness as load per task would be more stable (with the analysis point:1), and in case where the load increases beyond threshold, it would be more prompt to move such tasks to big CPUs without causing fake wake ups.
Thanks & Regards,
Rahul Khandelwal
-----Original Message----- From: Rahul Khandelwal (Rahul Khandelwal) Sent: 04 September 2015 23:11 To: 'ganguly.s@samsung.com'; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten.Rasmussen@arm.com; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: RE: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Dear All,
We further checked with some modifications in the code while making the decision for up migration.
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU,
We now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
We checked for the performance of this patch with the hackbench tool.
Results for 10 samples are;
Without patch
maximum time of execution 3.342secs
minimum time of execution 3.313secs
average of 10 samples: 3.368secs
With patch
maximum time of execution 3.319secs
minimum time of execution 3.071secs
average of 10 samples: 3.169secs
On an average with this patch we would have performance improvement of 5.90%.
This would essentially lead to have better responsiveness of scheduler to migrate the big tasks to big CPUs.
From e1df1fc8f069aafc592b42bc3fcc7780f32048a7 Mon Sep 17 00:00:00 2001
From: rahulkhandelwal <rahul.khandelwal@spreadtrum.com mailto:rahul.khandelwal@spreadtrum.com>
Date: Sat, 5 Sep 2015 01:35:23 +0800
Subject: [PATCH 1/1] HMP: send IPI to all available big idle CPUs till their exist any heavy task on slower domain CPUs
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU, we now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
CC: Sanjeev Yadav <sanjeev.yadav@spreadtrum.com mailto:sanjeev.yadav@spreadtrum.com>
CC: Gaurav Jindal <gaurav.jindal@spreadtrum.com mailto:gaurav.jindal@spreadtrum.com>
CC: sprd-ind-kernel-group@googlegroups.com mailto:sprd-ind-kernel-group@googlegroups.com
Signed-off-by: rahulkhandelwal <rahul.khandelwal@spreadtrum.com mailto:rahul.khandelwal@spreadtrum.com>
kernel/sched/fair.c | 188 ++++++++++++++++++++++++++++++++++++++++++---------
1 file changed, 155 insertions(+), 33 deletions(-)
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c index 1baf641..a81ad6c 100644
--- a/kernel/sched/fair.c
+++ b/kernel/sched/fair.c
@@ -7156,6 +7156,34 @@ out:
put_task_struct(p);}
+/*
- Update idle cpu for hmp_domain(faster or slower)
- Return 1 for Success(found idle cpu) otherwise 0
*/
+static inline unsigned int hmp_domain_idle_cpu(struct hmp_domain +*hmpd,
*idle_cpu, struct cpumask *affinity) {int cpu;unsigned long contrib;struct sched_avg *avg;struct cpumask temp_cpumask;cpumask_and(&temp_cpumask, &hmpd->cpus, affinity ? affinity :+cpu_online_mask);
for_each_cpu_mask(cpu, temp_cpumask) {avg = &cpu_rq(cpu)->avg;contrib = avg->load_avg_ratio;if (!contrib && !cpu_rq(cpu)->wake_for_idle_pull) {if (idle_cpu)*idle_cpu = cpu;return 1;}}return 0;+}
static DEFINE_SPINLOCK(hmp_force_migration);
/*
@@ -7164,23 +7192,125 @@ static DEFINE_SPINLOCK(hmp_force_migration);
*/
static void hmp_force_up_migration(int this_cpu) {
int cpu, target_cpu;
int cpu;int target_cpu = NR_CPUS; struct sched_entity *curr, *orig;
struct rq *target; unsigned long flags; unsigned int force, got_target; struct task_struct *p;
struct cpumask idle_cpus = {0};struct sched_avg *avg;struct sched_entity *se;struct rq *rq;int nr_count;
if (!spin_trylock(&hmp_force_migration))
struct cpumask *hmp_slowcpu_mask = NULL;struct cpumask *hmp_fastcpu_mask = NULL;u64 now;if (!spin_trylock(&hmp_force_migration)) return;
for_each_online_cpu(cpu) {
if(hmp_cpu_is_slowest(this_cpu)) {hmp_fastcpu_mask = &hmp_faster_domain(this_cpu)->cpus;hmp_slowcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;}else {hmp_fastcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;hmp_slowcpu_mask = &hmp_slower_domain(this_cpu)->cpus;}/* Check for idle_cpus in faster domain, *//* update the idle mask if load_avg_ratio = 0 */for_each_cpu(cpu, hmp_fastcpu_mask) {rq = cpu_rq(cpu);avg = &cpu_rq(cpu)->avg;if(avg->load_avg_ratio == 0)cpumask_set_cpu(cpu, &idle_cpus);}/* Don't iterate for slower domain, if no idle cpu in fasterdomain*/
if(cpumask_empty(&idle_cpus))goto DOWN;/* Iterate slower domain cpus for up migration*/for_each_cpu(cpu, hmp_slowcpu_mask) {if(!cpu_online(cpu)) {continue;}nr_count = hmp_max_tasks;rq = cpu_rq(cpu);raw_spin_lock_irqsave(&rq->lock, flags);curr = rq->cfs.curr;if (!curr || rq->active_balance) {raw_spin_unlock_irqrestore(&rq->lock, flags);continue;}if (!entity_is_task(curr)) {struct cfs_rq *cfs_rq;cfs_rq = group_cfs_rq(curr);while (cfs_rq) {curr = cfs_rq->curr;cfs_rq = group_cfs_rq(curr);}}/* The currently running task is not on the runqueue */se = __pick_first_entity(cfs_rq_of(curr));while(!cpumask_empty(&idle_cpus) && nr_count-- && se) {struct task_struct *p = task_of(se);/* Check for eligible task for up migration */if (entity_is_task(se) &&se->avg.load_avg_ratio > hmp_up_threshold &&cpumask_intersects(hmp_fastcpu_mask,tsk_cpus_allowed(p))) {
+#ifdef CONFIG_SCHED_HMP_PRIO_FILTER
/* Filter by task priority */if (p->prio >= hmp_up_prio) {se = __pick_next_entity(se);continue;}+#endif
/* Let the task load settle before doinganother
up migration */
/* hack - always use clock from first onlineCPU */
now =cpu_rq(cpumask_first(cpu_online_mask))->clock_task;
if (((now - se->avg.hmp_last_up_migration) >>
< hmp_next_up_threshold) {se = __pick_next_entity(se);continue;}/* Wakeup for eligible idle cpu in fasterdomain */
if(hmp_domain_idle_cpu(hmp_faster_domain(cpu),
&target_cpu,
tsk_cpus_allowed(p))) {cpu_rq(target_cpu)->wake_for_idle_pull =1;
cpumask_clear_cpu(target_cpu,&idle_cpus);
/* Update idle cpumask */
smp_send_reschedule(target_cpu);}}se = __pick_next_entity(se);}raw_spin_unlock_irqrestore(&rq->lock, flags);}+DOWN:
for_each_cpu(cpu, hmp_fastcpu_mask) {if(!cpu_online(cpu))continue; force = 0; got_target = 0;
target = cpu_rq(cpu);raw_spin_lock_irqsave(&target->lock, flags);curr = target->cfs.curr;if (!curr || target->active_balance) {raw_spin_unlock_irqrestore(&target->lock, flags);
rq = cpu_rq(cpu);raw_spin_lock_irqsave(&rq->lock, flags);curr = rq->cfs.curr;if (!curr || rq->active_balance) {raw_spin_unlock_irqrestore(&rq->lock, flags); continue; } if (!entity_is_task(curr)) {@@ -7193,19 +7323,7 @@ static void hmp_force_up_migration(int this_cpu)
} } orig = curr;
curr = hmp_get_heaviest_task(curr, -1);if (!curr) {raw_spin_unlock_irqrestore(&target->lock, flags);continue;}p = task_of(curr);if (hmp_up_migration(cpu, &target_cpu, curr)) {cpu_rq(target_cpu)->wake_for_idle_pull = 1;raw_spin_unlock_irqrestore(&target->lock, flags);spin_unlock(&hmp_force_migration);smp_send_reschedule(target_cpu);return;}
if (!got_target) { /* * For now we just check the currently running task.@@ -7214,13 +7332,13 @@ static void hmp_force_up_migration(int this_cpu)
*/ curr = hmp_get_lightest_task(orig, 1); p = task_of(curr);
target->push_cpu = hmp_offload_down(cpu, curr);if (target->push_cpu < NR_CPUS) {
rq->push_cpu = hmp_offload_down(cpu, curr);if (rq->push_cpu < NR_CPUS) { get_task_struct(p);
target->migrate_task = p;
rq->migrate_task = p; got_target = 1;
trace_sched_hmp_migrate(p, target->push_cpu,HMP_MIGRATE_OFFLOAD);
hmp_next_down_delay(&p->se, target->push_cpu);
trace_sched_hmp_migrate(p, rq->push_cpu,HMP_MIGRATE_OFFLOAD);
hmp_next_down_delay(&p->se, rq->push_cpu); } } /*@@ -7229,24 +7347,28 @@ static void hmp_force_up_migration(int this_cpu)
* CPU stopper take care of it. */ if (got_target) {
if (!task_running(target, p)) {
if (!task_running(rq, p)) { trace_sched_hmp_migrate_force_running(p, 0);
hmp_migrate_runnable_task(target);
hmp_migrate_runnable_task(rq); } else {
target->active_balance = 1;
rq->active_balance = 1; force = 1; } }
raw_spin_unlock_irqrestore(&target->lock, flags);
raw_spin_unlock_irqrestore(&rq->lock, flags); if (force)
stop_one_cpu_nowait(cpu_of(target),
stop_one_cpu_nowait(cpu_of(rq), hmp_active_task_migration_cpu_stop,
target, &target->active_balance_work);
rq, &rq->active_balance_work); }spin_unlock(&hmp_force_migration);}
/*
hmp_idle_pull looks at little domain runqueues to see
if a task should be pulled.
--
1.7.9.5
-----Original Message-----
From: Sarbojit Ganguly [mailto:ganguly.s@samsung.com]
Sent: 04 September 2015 08:46
To: Alex Shi; Rahul Khandelwal (Rahul Khandelwal); Sarbojit Ganguly; Jon Medhurst (Tixy)
Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org mailto:khilman@linaro.org; Morten.Rasmussen@arm.com mailto:Morten.Rasmussen@arm.com; vincent.guittot@linaro.org mailto:vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org mailto:linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com mailto:chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI
Subject: Re: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Rahul,
I will run hackbench with your patch and share the results. Lets see if we can get some measurable differences on the performance side.
Regards,
Sarbojit
------- Original Message -------
Sender : Alex Shi<alex.shi@linaro.org mailto:alex.shi@linaro.org>
Date : Aug 28, 2015 12:25 (GMT+05:30)
Title : Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Seems it is big saving...
On 08/25/2015 11:58 PM, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Sarbojit,
Agreed with your point, thanks for raising it..
There was one issue in the total no of interrupt count in the
previous
chart preparation, actually the total no of interrupt is equal to
the
interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big
domain CPUs. I just updated the below mentioned chart with the
related data.
?????
??? ?? ?? ??
----------------------------------------------------------------------+
The Tao lies beyond Yin and Yang. It is silent and still as a pool of water. |
It does not seek fame, therefore nobody knows its presence. |
It does not seek fortune, for it is complete within itself. |
It exists beyond space and time. |
----------------------------------------------------------------------+
-- #include <best/regards.h>
Patrick Bellasi
Hello Patrick,
As per this mail communication, there are 2 patches associated in this mail chain.
Can you please help for processing the patch dated September 04, 2015 : "HMP: Do not send IPI if core already waked up".
If it required detail processing then we are wondering if you could proceed with the old patch dated on August 14, 2015. This patch avoid sending of unnecessary interrupts to CPUs of faster domain.
Thanks & Regards, Rahul Khandelwal
-----Original Message----- From: Rahul Khandelwal (Rahul Khandelwal) Sent: 07 October 2015 14:02 To: 'Patrick Bellasi'; 'ganguly.s@samsung.com'; 'Alex Shi'; 'Jon Medhurst (Tixy)' Cc: 'Hiren Bharatbhai Gajjar'; 'khilman@linaro.org'; 'Morten Rasmussen'; 'vincent.guittot@linaro.org'; Gaurav Jindal (Gaurav Jindal); 'linaro-kernel@lists.linaro.org'; Sanjeev Yadav (Sanjeev Kumar Yadav); 'Chris Redpath'; 'SHARAN ALLUR'; 'VIKRAM MUPPARTHI'; 'SUNEEL KUMAR SURIMANI' Subject: RE: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Hello Patrick,
I was wondering if you could process the HMP patch discussed in trailing mail and help forward it at next step.
Thanks for your help.
Regards, Rahul Khandelwal
-----Original Message----- From: Rahul Khandelwal (Rahul Khandelwal) Sent: 18 September 2015 10:48 To: 'Patrick Bellasi'; ganguly.s@samsung.com; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten Rasmussen; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); Chris Redpath; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: RE: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Dear Patrick,
We have tested our modification on kernel v3.10.
Thanks & Regards, Rahul Khandelwal
-----Original Message----- From: Patrick Bellasi [mailto:patrick.bellasi@arm.com] Sent: 17 September 2015 20:42 To: Rahul Khandelwal (Rahul Khandelwal); ganguly.s@samsung.com; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten Rasmussen; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); Chris Redpath; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
On 17/09/15 14:11, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Patrick and Alex,
Hi Rahul, thanks for the analysis you did.
The patch you are proposing seems interesting but it is also actually changing a lot in the active load balance path. Our evaluation strategy requires to run a complete set of performance and _power_ analysis.
Unfortunately right now I'm a bit busy on the EAS side but I would like to give a try to your patch in one of the following weeks.
Could you tell me on which kernel exactly is that patch to be applied?
Thanks Patrick
This is with reference to further performance/responsiveness testing of the patch dated September 04, 2015.
The patch intended to focus on 3 major areas in hmp_force_up_migration
CPU Run queue spin lock duration.
Heavy task migration on IDLE CPU in faster domain
Eliminating the fake IPI to big CPUs.
We are sharing the results for further testing of the patch.
Following are the test results for:
- Running camera for 50 seconds. Here we are observing the load
behaviour of camera related threads.
cid:image001.png@01D0F177.25A30FB0
- Running browser with web page having images. we are observing the
load behaviour of browser related and display related threads.
cid:image002.png@01D0F177.25A30FB0
- We checked the time for which run queue is kept locked. With the
patch proposed, "the locking period is reduced considerably as compared to original" code behavior.
Analysis for the results:
1.In the patch, the time for which runqueue is locked, has been reduced during up migration, "runqueue for faster cpu domain should not be kept locked which is the case with current code and vice versa. The suggested changes would lead to more execution chance for a task on its CPU and thereby preventing the load to get heavy"
2.In complex scenarios, where the load on slower domain CPUs increases above threshold, IPI are sent to big CPUs thereby increasing the responsiveness of the scheduler to migrate the heavy tasks.
3.With the proposed patch , no false IPI would be sent thereby preventing the fake wake ups of big CPUs.
Therefore, the proposed modification in HMP would help to achieve better performance and increase CPU responsiveness as load per task would be more stable (with the analysis point:1), and in case where the load increases beyond threshold, it would be more prompt to move such tasks to big CPUs without causing fake wake ups.
Thanks & Regards,
Rahul Khandelwal
-----Original Message----- From: Rahul Khandelwal (Rahul Khandelwal) Sent: 04 September 2015 23:11 To: 'ganguly.s@samsung.com'; Alex Shi; Jon Medhurst (Tixy) Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org; Morten.Rasmussen@arm.com; vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI Subject: RE: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Dear All,
We further checked with some modifications in the code while making the decision for up migration.
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU,
We now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
We checked for the performance of this patch with the hackbench tool.
Results for 10 samples are;
Without patch
maximum time of execution 3.342secs
minimum time of execution 3.313secs
average of 10 samples: 3.368secs
With patch
maximum time of execution 3.319secs
minimum time of execution 3.071secs
average of 10 samples: 3.169secs
On an average with this patch we would have performance improvement of 5.90%.
This would essentially lead to have better responsiveness of scheduler to migrate the big tasks to big CPUs.
From e1df1fc8f069aafc592b42bc3fcc7780f32048a7 Mon Sep 17 00:00:00 2001
From: rahulkhandelwal <rahul.khandelwal@spreadtrum.com mailto:rahul.khandelwal@spreadtrum.com>
Date: Sat, 5 Sep 2015 01:35:23 +0800
Subject: [PATCH 1/1] HMP: send IPI to all available big idle CPUs till their exist any heavy task on slower domain CPUs
In place of fetching the heaviest task on slower domain and then searching for idle CPU in big domain and then sending IPI to big CPU, we now first look for the idle CPUs on the bigger domain and then send IPI to big idle CPUs till their exist any heavy task on slower domain CPUs.
CC: Sanjeev Yadav <sanjeev.yadav@spreadtrum.com mailto:sanjeev.yadav@spreadtrum.com>
CC: Gaurav Jindal <gaurav.jindal@spreadtrum.com mailto:gaurav.jindal@spreadtrum.com>
CC: sprd-ind-kernel-group@googlegroups.com mailto:sprd-ind-kernel-group@googlegroups.com
Signed-off-by: rahulkhandelwal <rahul.khandelwal@spreadtrum.com mailto:rahul.khandelwal@spreadtrum.com>
kernel/sched/fair.c | 188 ++++++++++++++++++++++++++++++++++++++++++---------
1 file changed, 155 insertions(+), 33 deletions(-)
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c index 1baf641..a81ad6c 100644
--- a/kernel/sched/fair.c
+++ b/kernel/sched/fair.c
@@ -7156,6 +7156,34 @@ out:
put_task_struct(p);}
+/*
- Update idle cpu for hmp_domain(faster or slower)
- Return 1 for Success(found idle cpu) otherwise 0
*/
+static inline unsigned int hmp_domain_idle_cpu(struct hmp_domain +*hmpd,
*idle_cpu, struct cpumask *affinity) {int cpu;unsigned long contrib;struct sched_avg *avg;struct cpumask temp_cpumask;cpumask_and(&temp_cpumask, &hmpd->cpus, affinity ? affinity :+cpu_online_mask);
for_each_cpu_mask(cpu, temp_cpumask) {avg = &cpu_rq(cpu)->avg;contrib = avg->load_avg_ratio;if (!contrib && !cpu_rq(cpu)->wake_for_idle_pull) {if (idle_cpu)*idle_cpu = cpu;return 1;}}return 0;+}
static DEFINE_SPINLOCK(hmp_force_migration);
/*
@@ -7164,23 +7192,125 @@ static DEFINE_SPINLOCK(hmp_force_migration);
*/
static void hmp_force_up_migration(int this_cpu) {
int cpu, target_cpu;
int cpu;int target_cpu = NR_CPUS; struct sched_entity *curr, *orig;
struct rq *target; unsigned long flags; unsigned int force, got_target; struct task_struct *p;
struct cpumask idle_cpus = {0};struct sched_avg *avg;struct sched_entity *se;struct rq *rq;int nr_count;
if (!spin_trylock(&hmp_force_migration))
struct cpumask *hmp_slowcpu_mask = NULL;struct cpumask *hmp_fastcpu_mask = NULL;u64 now;if (!spin_trylock(&hmp_force_migration)) return;
for_each_online_cpu(cpu) {
if(hmp_cpu_is_slowest(this_cpu)) {hmp_fastcpu_mask = &hmp_faster_domain(this_cpu)->cpus;hmp_slowcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;}else {hmp_fastcpu_mask = &hmp_cpu_domain(this_cpu)->cpus;hmp_slowcpu_mask = &hmp_slower_domain(this_cpu)->cpus;}/* Check for idle_cpus in faster domain, *//* update the idle mask if load_avg_ratio = 0 */for_each_cpu(cpu, hmp_fastcpu_mask) {rq = cpu_rq(cpu);avg = &cpu_rq(cpu)->avg;if(avg->load_avg_ratio == 0)cpumask_set_cpu(cpu, &idle_cpus);}/* Don't iterate for slower domain, if no idle cpu in fasterdomain*/
if(cpumask_empty(&idle_cpus))goto DOWN;/* Iterate slower domain cpus for up migration*/for_each_cpu(cpu, hmp_slowcpu_mask) {if(!cpu_online(cpu)) {continue;}nr_count = hmp_max_tasks;rq = cpu_rq(cpu);raw_spin_lock_irqsave(&rq->lock, flags);curr = rq->cfs.curr;if (!curr || rq->active_balance) {raw_spin_unlock_irqrestore(&rq->lock, flags);continue;}if (!entity_is_task(curr)) {struct cfs_rq *cfs_rq;cfs_rq = group_cfs_rq(curr);while (cfs_rq) {curr = cfs_rq->curr;cfs_rq = group_cfs_rq(curr);}}/* The currently running task is not on the runqueue */se = __pick_first_entity(cfs_rq_of(curr));while(!cpumask_empty(&idle_cpus) && nr_count-- && se) {struct task_struct *p = task_of(se);/* Check for eligible task for up migration */if (entity_is_task(se) &&se->avg.load_avg_ratio > hmp_up_threshold &&cpumask_intersects(hmp_fastcpu_mask,tsk_cpus_allowed(p))) {
+#ifdef CONFIG_SCHED_HMP_PRIO_FILTER
/* Filter by task priority */if (p->prio >= hmp_up_prio) {se = __pick_next_entity(se);continue;}+#endif
/* Let the task load settle before doinganother
up migration */
/* hack - always use clock from first onlineCPU */
now =cpu_rq(cpumask_first(cpu_online_mask))->clock_task;
if (((now - se->avg.hmp_last_up_migration) >>
< hmp_next_up_threshold) {se = __pick_next_entity(se);continue;}/* Wakeup for eligible idle cpu in fasterdomain */
if(hmp_domain_idle_cpu(hmp_faster_domain(cpu),
&target_cpu,
tsk_cpus_allowed(p))) {cpu_rq(target_cpu)->wake_for_idle_pull =1;
cpumask_clear_cpu(target_cpu,&idle_cpus);
/* Update idle cpumask */
smp_send_reschedule(target_cpu);}}se = __pick_next_entity(se);}raw_spin_unlock_irqrestore(&rq->lock, flags);}+DOWN:
for_each_cpu(cpu, hmp_fastcpu_mask) {if(!cpu_online(cpu))continue; force = 0; got_target = 0;
target = cpu_rq(cpu);raw_spin_lock_irqsave(&target->lock, flags);curr = target->cfs.curr;if (!curr || target->active_balance) {raw_spin_unlock_irqrestore(&target->lock, flags);
rq = cpu_rq(cpu);raw_spin_lock_irqsave(&rq->lock, flags);curr = rq->cfs.curr;if (!curr || rq->active_balance) {raw_spin_unlock_irqrestore(&rq->lock, flags); continue; } if (!entity_is_task(curr)) {@@ -7193,19 +7323,7 @@ static void hmp_force_up_migration(int this_cpu)
} } orig = curr;
curr = hmp_get_heaviest_task(curr, -1);if (!curr) {raw_spin_unlock_irqrestore(&target->lock, flags);continue;}p = task_of(curr);if (hmp_up_migration(cpu, &target_cpu, curr)) {cpu_rq(target_cpu)->wake_for_idle_pull = 1;raw_spin_unlock_irqrestore(&target->lock, flags);spin_unlock(&hmp_force_migration);smp_send_reschedule(target_cpu);return;}
if (!got_target) { /* * For now we just check the currently running task.@@ -7214,13 +7332,13 @@ static void hmp_force_up_migration(int this_cpu)
*/ curr = hmp_get_lightest_task(orig, 1); p = task_of(curr);
target->push_cpu = hmp_offload_down(cpu, curr);if (target->push_cpu < NR_CPUS) {
rq->push_cpu = hmp_offload_down(cpu, curr);if (rq->push_cpu < NR_CPUS) { get_task_struct(p);
target->migrate_task = p;
rq->migrate_task = p; got_target = 1;
trace_sched_hmp_migrate(p, target->push_cpu,HMP_MIGRATE_OFFLOAD);
hmp_next_down_delay(&p->se, target->push_cpu);
trace_sched_hmp_migrate(p, rq->push_cpu,HMP_MIGRATE_OFFLOAD);
hmp_next_down_delay(&p->se, rq->push_cpu); } } /*@@ -7229,24 +7347,28 @@ static void hmp_force_up_migration(int this_cpu)
* CPU stopper take care of it. */ if (got_target) {
if (!task_running(target, p)) {
if (!task_running(rq, p)) { trace_sched_hmp_migrate_force_running(p, 0);
hmp_migrate_runnable_task(target);
hmp_migrate_runnable_task(rq); } else {
target->active_balance = 1;
rq->active_balance = 1; force = 1; } }
raw_spin_unlock_irqrestore(&target->lock, flags);
raw_spin_unlock_irqrestore(&rq->lock, flags); if (force)
stop_one_cpu_nowait(cpu_of(target),
stop_one_cpu_nowait(cpu_of(rq), hmp_active_task_migration_cpu_stop,
target, &target->active_balance_work);
rq, &rq->active_balance_work); }spin_unlock(&hmp_force_migration);}
/*
hmp_idle_pull looks at little domain runqueues to see
if a task should be pulled.
--
1.7.9.5
-----Original Message-----
From: Sarbojit Ganguly [mailto:ganguly.s@samsung.com]
Sent: 04 September 2015 08:46
To: Alex Shi; Rahul Khandelwal (Rahul Khandelwal); Sarbojit Ganguly; Jon Medhurst (Tixy)
Cc: Hiren Bharatbhai Gajjar; khilman@linaro.org mailto:khilman@linaro.org; Morten.Rasmussen@arm.com mailto:Morten.Rasmussen@arm.com; vincent.guittot@linaro.org mailto:vincent.guittot@linaro.org; Gaurav Jindal (Gaurav Jindal); linaro-kernel@lists.linaro.org mailto:linaro-kernel@lists.linaro.org; Sanjeev Yadav (Sanjeev Kumar Yadav); chris.redpath@arm.com mailto:chris.redpath@arm.com; Patrick Bellasi; SHARAN ALLUR; VIKRAM MUPPARTHI; SUNEEL KUMAR SURIMANI
Subject: Re: Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Rahul,
I will run hackbench with your patch and share the results. Lets see if we can get some measurable differences on the performance side.
Regards,
Sarbojit
------- Original Message -------
Sender : Alex Shi<alex.shi@linaro.org mailto:alex.shi@linaro.org>
Date : Aug 28, 2015 12:25 (GMT+05:30)
Title : Re: [PATCH 1/1] HMP: Do not send IPI if core already waked up
Seems it is big saving...
On 08/25/2015 11:58 PM, Rahul Khandelwal (Rahul Khandelwal) wrote:
Dear Sarbojit,
Agreed with your point, thanks for raising it..
There was one issue in the total no of interrupt count in the
previous
chart preparation, actually the total no of interrupt is equal to
the
interrupt sent to Idle core.
On an average we are saving more than 25% of the IPIs sent to big
domain CPUs. I just updated the below mentioned chart with the
related data.
?????
??? ?? ?? ??
----------------------------------------------------------------------+
The Tao lies beyond Yin and Yang. It is silent and still as a pool of water. |
It does not seek fame, therefore nobody knows its presence. |
It does not seek fortune, for it is complete within itself. |
It exists beyond space and time. |
----------------------------------------------------------------------+
-- #include <best/regards.h>
Patrick Bellasi
linaro-kernel@lists.linaro.org
-
 Patrick Bellasi
Patrick Bellasi -
 Rahul Khandelwal (Rahul Khandelwal)
Rahul Khandelwal (Rahul Khandelwal) -
 Sarbojit Ganguly
Sarbojit Ganguly